48 冒泡排序和希尔排序
冒泡排序
-
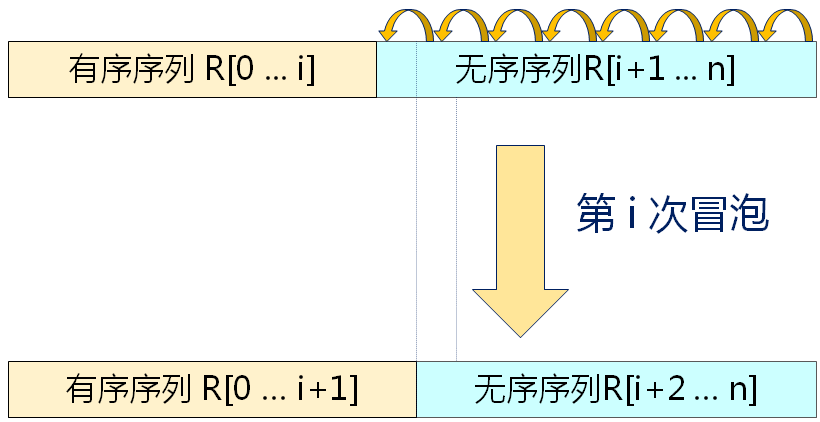
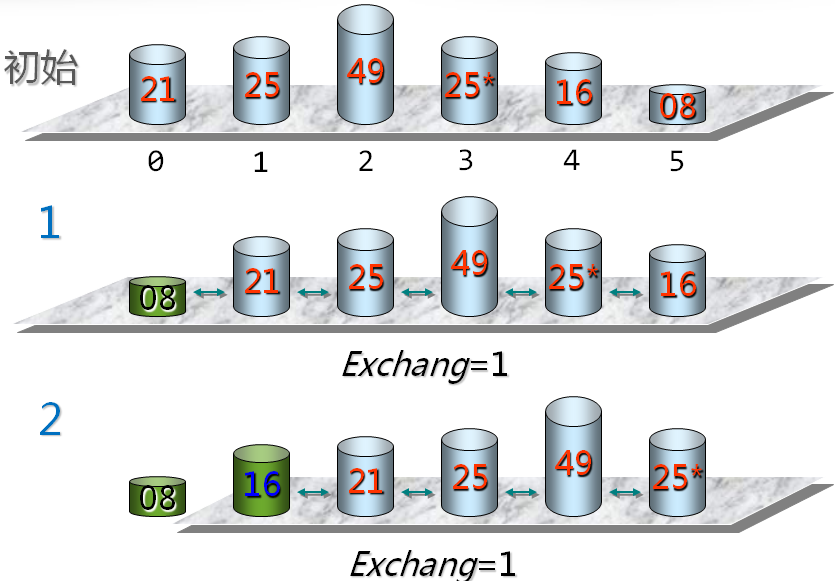
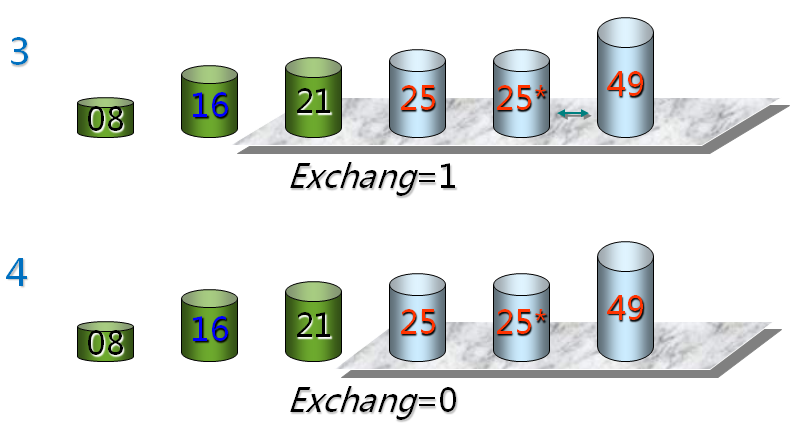
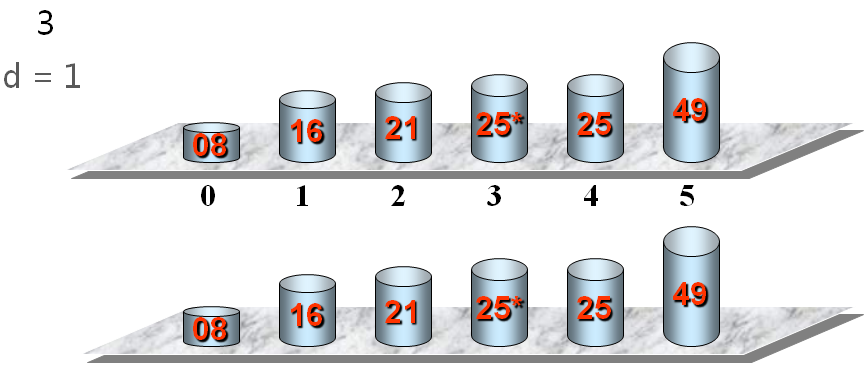
冒泡排序的基本思想 每次从后向前进行(假设为第i次),j=n-1,n-2,...,i,两两比较V[j-1]和V[j]的关键字;如果发生逆序,则交换V[j-1]和V[j]。
-
第i次冒泡排序示例
编程实验(一)
-
冒泡排序的实现
希尔排序
-
希尔排序的基本思想
- 将待排序列划分为若干组,在每一组内进行插入排序,以使整个序列基本有序,然后再对整个序列进行插入排序。
-
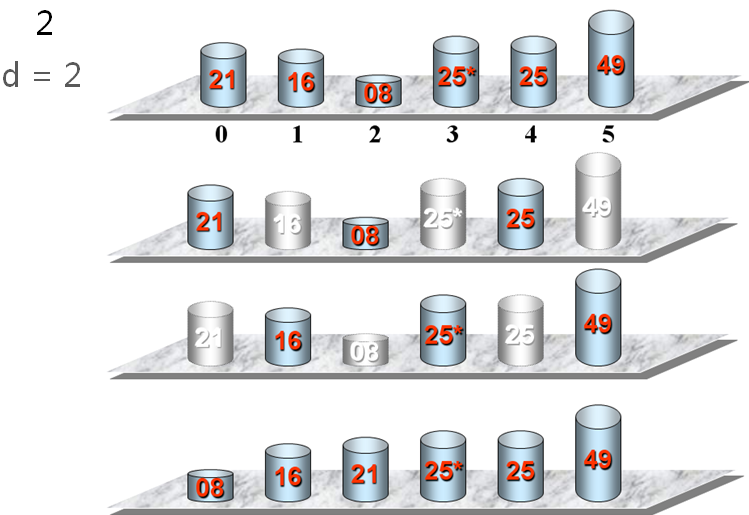
希尔排序示例 例如:将n个数据元素分成d个子序列:
{R[1],R[1+d],R[1+2d,...,R[1+kd]}{R[2],R[2+d],R[2+2d,...,R[2+kd]}...{R[d],R[2d],R[3d,...,R[(k+1)d]}其中,d称为增量,他的值在排序过程中从大到小逐渐缩小,直至最后一趟排序减为1。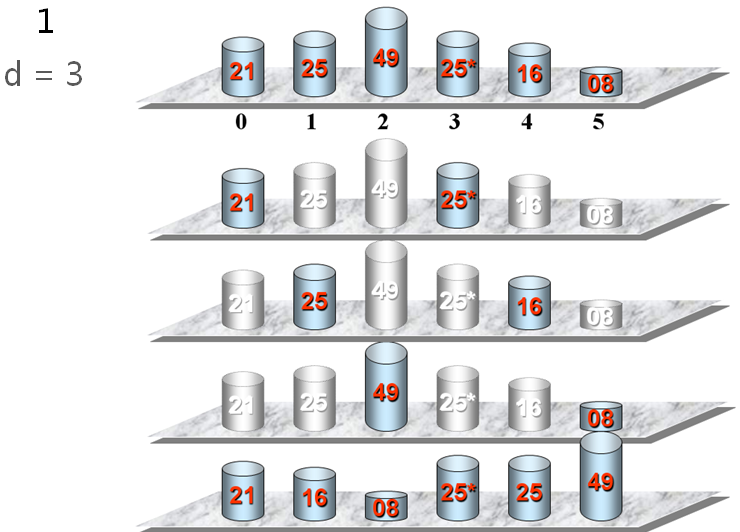
编程实验(二)
-
希尔排序的实现
小结
- 冒泡排序每次从后向前将较小的元素交互到位
- 冒泡排序是一种稳定的排序法,其复杂度为O(n2)
- 希尔排序通过分组的方式进行多次插入排序
- 希尔排序是一种不稳定的排序法,其复杂度为O(n3/2)
49 归并排序和快速排序
归并排序
-
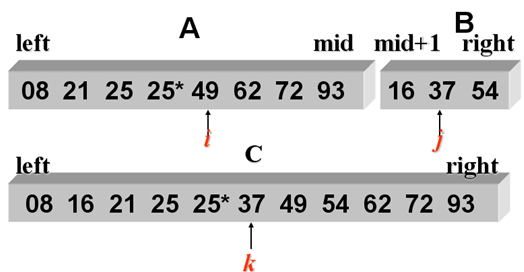
归并排序的基本思想 将两个或两个以上的有序序列合并成一个新的有序序列 有序序列V[0]...V[m]和V[m+1]..V[n-1] → V[0]...V[n-1] 这种归并方法称为2路归并。
-
归并的套路
- 将3个有序序列归并为一个新的有序序列,称为3路归并
- 将N个有序序列归并为一个新的有序序列,称为N路归并
- 将多个有序序列归并为一个新的有序序列,称为多路归并
-
2路归并示例

-
归并排序的代码实现
编程实验(一)
-
归并排序的实现
template<typename T>
class Sort{
public:
static void merge(T array[],size_t length) {
auto helper = new T[length];
merge(array,helper,0,length-1);
delete[] helper;
}
protected:
static void merge(T array[],T helper[],size_t begin,size_t end) {
if(begin>=end) return;
auto middle = (begin+end)/2;
merge(array,helper,begin,middle);
merge(array,helper,middle+1,end);
merge(array,helper,begin,middle,end);
}
static void merge(T array[],T helper[],size_t begin,size_t middle,size_t end) {
auto i = begin,j = middle+1,k = begin;
while((i<=middle)&&(j<=end)){
if(array[i]<=array[j]) helper[k++]=array[i++];
else helper[k++]=array[j++];
}
while(i<=middle) helper[k++]=array[i++];
while(j<=end) helper[k++]=array[j++];
for(i=begin;i<=end;i++) array[i]=helper[i];
}
};
快速排序
-
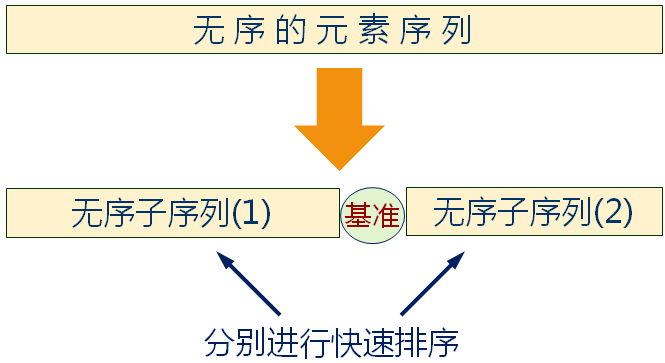
快速排序的基本思想
- 任取序列中的某个数据元素作为基准将整个序列划分为左右两个子序列
- 左侧子序列中所有元素都小于或等于基准元素
- 右侧子序列中所有元素都大于基准元素
- 基准元素排在这两个子序列中间
- 分别对这两个子序列重复进行划分,直到所有的数据元素都排在相应的位置上为止
- 任取序列中的某个数据元素作为基准将整个序列划分为左右两个子序列
-
快速排序示例
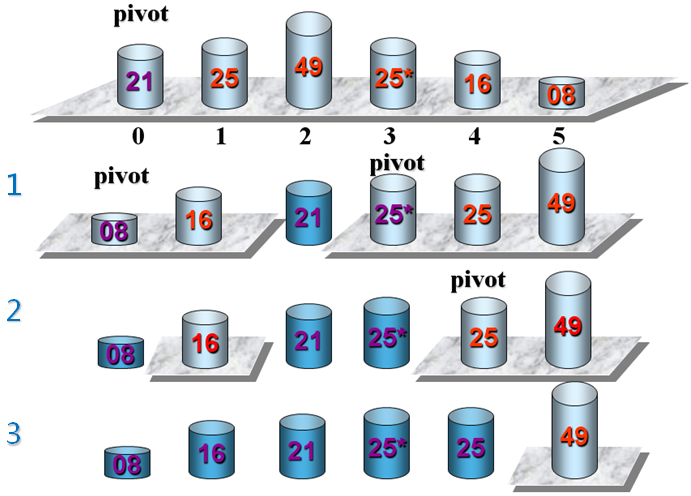
编程实验(二)
-
快速排序的实现
template<typename T>
class Sort{
public:
static void quick(T array[],size_t length){
quick(array,0,length-1);
}
protected:
static void swap(T &a,T &b){T c = a;a = b;b = c;}
static void quick(T array[],size_t begin,size_t end){
if(begin>=end) return;
auto pivot = partition(array,begin,end);
if(pivot>0) quick(array,begin,pivot-1);
quick(array,pivot+1,end);
}
static size_t partition(T array[],size_t begin,size_t end){
auto pivot = array[begin];
while(begin<end){
while((begin<end)&&(array[end]>pivot)) end--;
swap(array[begin],array[end]);
while((begin<end)&&(array[begin]<=pivot)) begin++;
swap(array[begin],array[end]);
}
return begin;
}
};
小结
- 归并排序需要额外的辅助空间才能完成,空间复杂度为O(n)
- 归并排序的时间复杂度为O(n*logn),是一种稳定的排序法
- 快速排序通过递归的方式对排序进行划分
- 快速排序的时间复杂度为O(n*logn),是一种不稳定的排序法
50 排序的工程应用示例
排序的工程应用示例(一)
-
排序类(Sort)与数组类(Array)的关系
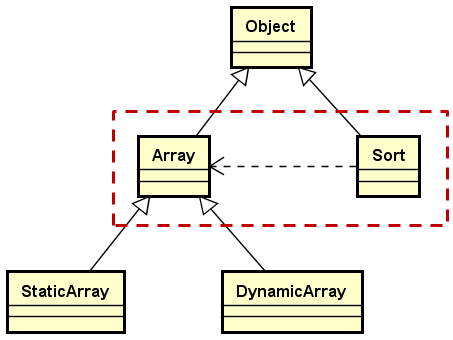
-
新增的成员函数
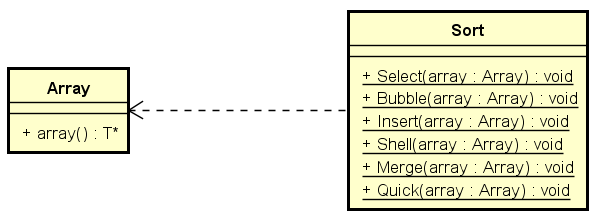
编程实验(一)
-
排序类与数组类的关系
排序的工程应用示例(二)
-
问题
当待排数据元素为体积庞大的对象时,如何提高排序的效率?
-
问题示例
struct Test : public Object {
int id;
int data1[1000];
double data2[500];
};
Test t[1000];
//... ...
Sort::Bubble(t,1000,false);
//... ... -
问题分析
- 排序过程中不可避免的需要进行交互操作
- 交换操作的本质为数据元素间的相互复制
- 当数据元素体积较大时,交换操作耗时巨大
-
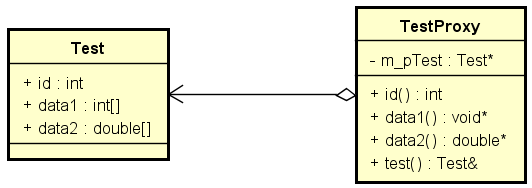
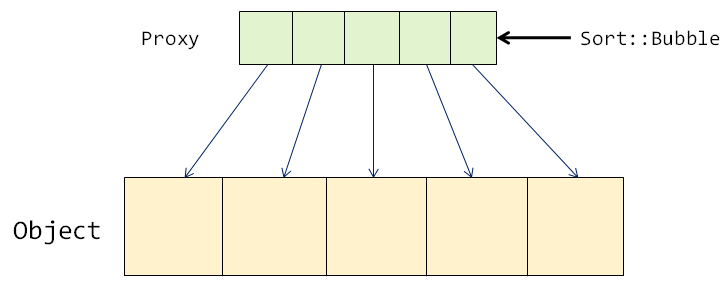
解决方案:代理模式
- 为待排数据元素设置代理对象
- 对代理对象所组成的序列进行排序
- 需要访问有序数据元素时,通过访问代理序列完成
-
真的能够提高排序效率吗?
编程实验(二)
-
解决方案
小结
- KylinLib中的排序类和数组类之间存在关联关系
- 排序类能够对数组类对象进行排序
- 当排序体积庞大的对象时,使用代理模式间接完成
- 代理模式的使用有效避免开大对象交换时的耗时操作
- 代理模式解决方案是空间换时间思想的体现