在我们现在的计算机技术体系中,存在这很多的网络通信协议。所谓通信协议,就是一段数据,通信双方事先约定好按规定的格式去编码和解码,最终达到传输消息的目的。在所有协议中,TCP/IP 协议是我们目前各种计算机设备最常用的协议,当然,TCP/IP 协议是一个协议簇,包含一组协议,其中靠近应用层最常用的是 TCP 和 UDP 协议。已经有太多的计算机书籍介绍它们了,这里就不再重复了。本专题介绍的内容主要是后台开发中关于应用层的协议的设计需要理解的原理和注意事项。本专题主要介绍面向连接的 TCP 协议。
TCP 协议是流式协议
很多读者从接触网络知识以来,应该听说过这句话:TCP 协议是流式协议。那么这句话到底是什么意思呢?所谓流式协议,即协议的内容是像流水一样的字节流,内容与内容之间没有明确的分界标志,需要我们人为地去给这些协议划分边界。
举个例子,A 与 B 进行 TCP 通�信,A 先后给 B 发送了一个 100 字节和 200 字节的数据包,那么 B 是如何收到呢?B 可能先收到 100 字节,再收到 200 字节;也可能先收到 50 字节,再收到 250 字节;或者先收到 100 字节,再收到 100 字节,再收到 100 字节;或者先收到 20 字节,再收到 20 字节,再收到 60 字节,再收到 100 字节,再收到 50 字节,再收到 50 字节……
不知道读者看出规律没有?规律就是 A 一共给 B 发送了 300 字节,B 可能以一次或者多次任意形式的总数为 300 字节收到。假设 A 给 B 发送的 100 字节和 200 字节分别都是一个数据包,对于发送端 A 来说,这个是可以区分的,但是对于 B 来说,如果不人为规定多长为一个数据包,B 每次是不知道应该把收到的数据中多少字节作为一个有效的数据包的。而规定每次把多少数据当成一个包就是协议格式规范的内容之一。
经常会有新手写出类似下面这样的代码:
发送端:
//...省略创建socket,建立连接等部分不相关的逻辑...
char buf[] = "the quick brown fox jumps over a lazy dog.";
int n = send(socket, buf, strlen(buf), 0);
//...省略出错处理逻辑...
接收端:
//省略创建socket,建立连接等部分不相关的逻辑...
char recvBuf[50] = { 0 };
int n = recv(socket, recvBuf, 50, 0);
//省略出错处理逻辑...
printf("recvBuf: %s", recvBuf);
为了专注问题本身的讨论,我这里省略掉了建立连接和部分错误处理的逻辑。上述代码中发送端给接收端发送了一串字符”the quick brown fox jumps over a lazy dog.“,接收端收到后将其打印出来。
类似这样的代码在本机一般会工作的很好,接收端也如期打印出来预料的字符串,但是一放到局域网或者公网环境就出问题了,即接收端可能打印出来字符串并不完整;如果发送端连续多次发送字符串,接收端会打印出来的字符串不完整或出现乱码。不完整的原因很好理解,即对端某次收到的数据小于完整字符串的长度,recvBuf 数组开始被清空成 0,收到部分字符串后,该字符串的末尾仍然是 0,printf 函数寻找以 0 为结束标志的字符结束输出;乱码的原因是如果某次收入的数据不仅包含一个完整的字符串,还包含下一个字符串部分内容,那么 recvBuf 数组将会被填满,printf 函数输出时仍然会寻找以 0 为结束标志的字符结束输出,这样读取的内存就越界了,一直找到为止,而越界后的内存可能是一些不可读字符,显示出来后就乱码了。
我举这个例子希望你明白 能对TCP 协议是流式协议有一个直观的认识。正因为如此,所以我们需要人为地在发送端和接收端规定每一次的字节流边界,以便接收端知道从什么位置取出多少字节来当成一个数据包去解析,这就是我们设计网络通信协议格式的要做的工作之一。
如何解决粘包问题
网络通信程序实际开发中,或者技术面试时,面试官通常会问的比较多的一个问题是:网络通信时,如何解决粘包?
有的面试官可能会这么问:网络通信时,如何解决粘包、丢包或者包乱序问题?这个问题其实是面试官在考察面试者的网络基础知识,如果是 TCP 协议,在大多数场景下,是不存在丢包和包乱序问题的,TCP 通信是可靠通信方式,TCP 协议栈通过序列号和包重传确认机制保证数据包的有序和一定被正确发到目的地;如果是 UDP 协议,如果不能接受少量丢包,那就要自己在 UDP 的基础上实现类似 TCP 这种有序和可靠传输机制了(例如 RTP协议、RUDP 协议)。所以,问题拆解后,只剩下如何解决粘包的问题。
先来解释一下什么是粘包,所谓粘包就是连续给对端发送两个或者两个以上的数据包,对端在一次收取中可能收到的数据包大于 1 个,大于2个,可能是几个(包括一个)包加上某个包的部分,或者干脆就是几个完整的包在一起。当然,也可能收到的数据只是一个包的部分,这种情况一般也叫半包。
无论是半包还是粘包问题,其根源是上文介绍中 TCP 协议是流式数据格式。解决问题的思路还是想办法从收到的数据中把包与包的边界给区分出来。那么如何区分呢?目前主要有三种方法:
固定包长的数据包
顾名思义,即每个协议包的长度都是固定的。��举个例子,例如我们可以规定每个协议包的大小是 64 个字节,每次收满 64 个字节,就取出来解析(如果不够,就先存起来)。
这种通信协议的格式简单但灵活性差。如果包内容不足指定的字节数,剩余的空间需要填充特殊的信息,如 \0(如果不填充特殊内容,如何区分包里面的正常内容与填充信息呢?);如果包内容超过指定字节数,又得分包分片,需要增加额外处理逻辑——在发送端进行分包分片,在接收端重新组装包片(分包和分片内容在接下来会详细介绍)。
以指定字符(串)为包的结束标志
这种协议包比较常见,即字节流中遇到特殊的符号值时就认为到一个包的末尾了。例如,我们熟悉的 FTP协议,发邮件的 SMTP 协议,一个命令或者一段数据后面加上”\r\n”(即所谓的 CRLF)表示一个包的结束。对端收到后,每遇到一个”\r\n“就把之前的数据当做一个数据包。
这种协议一般用于一些包含各种命令控制的应用中,其不足之处就是如果协议数据包内容部分需要使用包结束标志字符,就需要对这些字符做转码或者转义操作,以免被接收方错误地当成包结束标志而误解析。
包头 + 包体格式
这种格式的包一般分为两部分,即包头和包体,包头是固定大小的,且包头中必须含�有一个字段来说明接下来的包体有多大。
例如:
struct msg_header {
int32_t bodySize;
int32_t cmd;
};
这就是一个典型的包头格式,bodySize 指定了这个包的包体是多大。由于包头大小是固定的(这里是 size(int32_t) + sizeof(int32_t) = 8 字节),对端先收取包头大小字节数目(当然,如果不够还是先缓存起来,直到收够为止),然后解析包头,根据包头中指定的包体大小来收取包体,等包体收够了,就组装成一个完整的包来处理。在有些实现中,包头中的 bodySize可能被另外一个叫 packageSize 的字段代替,这个字段的含义是整个包的大小,这个时候,我们只要用 packageSize 减去包头大小(这里是 sizeof(msg_header))就能算出包体的大小,原理同上。
在使用大多数网络库时,通常你需要根据协议格式自己给数据包分界和解析,一般的网络库不提供这种功能是出于需要支持不同的协议,由于协议的不确定性,因此没法预先提供具体解包代码。当然,这不是绝对的,也有一些网络库提供了这种功能。在 Java Netty 网络框架中,提供了FixedLengthFrameDecoder 类去处理长度是定长的协议包,提供了 DelimiterBasedFrameDecoder 类去处理按特殊字符作为结束符的协议包,提供 ByteToMessageDecoder 去处理自定义格式的协议包(可用来处理包头 + 包体 这种格式的数据包),然而在继承 ByteToMessageDecoder 子类中你需要根据你的协议具体格式重写 decode() 方法来对数据包解包。
这三种包格式,希望读者能在理解其原理和优缺点的基础上深入掌握。
解包与处理
在理解了前面介绍的数据包的三种格式后,我们来介绍一下针对上述三种格式的数据包技术上应该如何处理。其处理流程都是一样的,这里我们以包头 + 包体 这种格式的数据包来说明。处理流程如下:
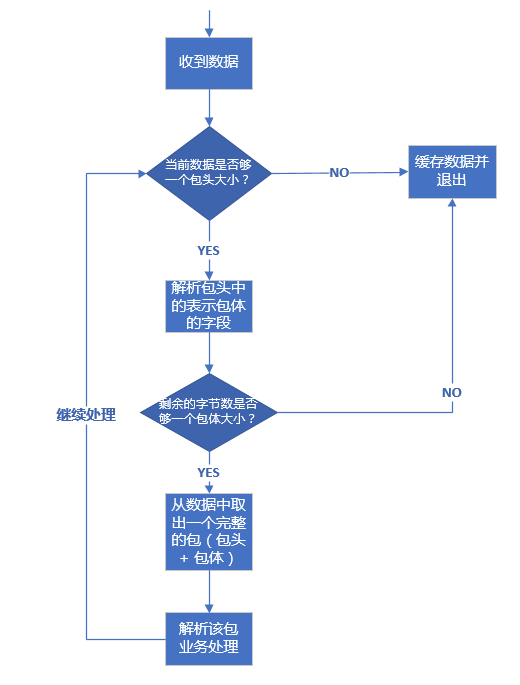
假设我们的包头格式如下:
//强制一字节对齐
#pragma pack(push, 1)
//协议头
struct msg_header
{
int32_t bodysize; //包体大小
};
#pragma pack(pop)
那么上面的流程实现代码如下:
//包最大字节数限制为10M
#define MAX_PACKAGE_SIZE 10 * 1024 * 1024
void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime) {
while (true) {
//不够一个包头大小
if (pBuffer->readableBytes() < (size_t)sizeof(msg_header)) {
return;
}
//取包头信息
msg_header header;
memcpy(&header, pBuffer->peek(), sizeof(msg_header));
//包头有错误,立即关闭连接
if (header.bodysize <= 0 || header.bodysize > MAX_PACKAGE_SIZE) {
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.bodysize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
//inbuf用来存放当前要处理的包
std::string inbuf;
inbuf.append(pBuffer->peek(), header.bodysize);
pBuffer->retrieve(header.bodysize);
//解包和业务处理
if (!Process(conn, inbuf.c_str(), inbuf.length())) {
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
}// end while-loop
}
上述流程代码的处理过程和流程图中是一致的,pBuffer 这里是一个自定义的接收缓冲区,这里的代码,已经将收到的数据放入了这个缓冲区,所以判断当前已收取的字节数目只需要使用这个对象的相应方法即可。上述代码有些细节我需要强调一下:
- 取包头时,你应该拷贝一份数据包头大小的数据出来,而不是从缓冲区 pBuffer 中直接将数据取出来(即取出来的数据从 pBuffer 中移除),这是因为倘若接下来根据包头中的字段得到包体大小时,如果剩余数据不够一个包体大小,你又得把这个包头数据放回缓冲区。为了避免这种不必要的操作,只有缓冲区数据大小够整个包的大小(代码中:header.bodysize + sizeof(msg))你才需要把整个包大小的数据从缓冲区移除,这也是这里的 pBuffer->peek() 方法 peek 单词的含义(中文可以翻译成”瞟一眼“或者”偷窥“)。
- 通过包头得到包体大小时,你一定要对 bodysize 的数值进行校验,我这里要求 bodysize 必须大于 0 且不大于 10 * 1024 * 1024(即 10 M)。当然,实际开发中,你可以根据你自己的需求要决定 bodysize 的上下限(包体大小是 0 字节的包在某些业务场景下是允许的)。记住,一定要判断这个上下限,因为假设这是一个非法的客户端发来的数�据,其 bodysize 设置了一个比较大的数值,例如 1 * 1024 * 1024 * 1024(即 1 G),你的逻辑会让你一直缓存该客户端发来的数据,那么很快你的服务器内存将会被耗尽,操作系统在检测到你的进程占用内存达到一定阈值时会杀死你的进程,导致服务不能再正常对外服务。如果你检测了 bodysize 字段的是否满足你设置的上下限,对于非法的 bodysize,直接关闭这路连接即可。这也是服务的一种自我保护措施,避免因为非法数据包带来的损失。还有另外一种情况下 bodysize 也可能不是预期的合理值,即因为网络环境差或者某次数据解析逻辑错误,导致后续的数据错位,把不该当包头数据的数据当成了包头,这个时候解析出来的 bodysize 也可能不是合理值,同样,这种情形下也会被这段检验逻辑检测到,最终关闭连接。
- 不知道你有没有注意到整个判断包头、包体以及处理包的逻辑放在一个 while 循环里面,这是必要的。如果没有这个 while 循环,当你一次性收到多个包时,你只会处理一个,下次接着处理就需要等到新一批数据来临时再次触发这个逻辑。这样造成的结果就是,对端给你发送了多个请求,你最多只能应答一个,后面的应答得等到对端再次给你发送数据时。这就是对粘包逻辑的正确处理。
以上逻辑和代码是最基本的粘包和半包处理机制,也就是所谓的技术上的解包处理逻辑(业务上的解包处理逻辑后面章节再介绍)。希望读者能理解他们,在理解了他们的基础之上,我们可以给解包拓展很多功能,例如,我们再给我们的协议包增加一个支持压缩的功能,我们的包头变成下面这个样子:
#pragma pack(push, 1)
//协议头
struct msg_header
{
char compressflag; //压缩标志,如果为1,则启用压缩,反之不启用压缩
int32_t originsize; //包体压缩前大小
int32_t compresssize; //包体压缩后大小
char reserved[16]; //保留字段,用于将来拓展
};
#pragma pack(pop)
修改后的代码如下:
//包最大字节数限制为10M
#define MAX_PACKAGE_SIZE 10 * 1024 * 1024
void ChatSession::OnRead(const std::shared_ptr<TcpConnection>& conn, Buffer* pBuffer, Timestamp receivTime) {
while (true) {
//不够一个包头大小
if (pBuffer->readableBytes() < (size_t)sizeof(msg_header)) {
return;
}
//取包头信息
msg_header header;
memcpy(&header, pBuffer->peek(), sizeof(msg_header));
//数据包压缩过
if (header.compressflag == PACKAGE_COMPRESSED) {
//包头有错误,立即关闭连接
if (header.compresssize <= 0 || header.compresssize > MAX_PACKAGE_SIZE ||
header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE) {
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.compresssize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
std::string inbuf;
inbuf.append(pBuffer->peek(), header.compresssize);
pBuffer->retrieve(header.compresssize);
std::string destbuf;
if (!ZlibUtil::UncompressBuf(inbuf, destbuf, header.originsize)) {
conn->forceClose();
return;
}
//业务逻辑处理
if (!Process(conn, destbuf.c_str(), destbuf.length())){
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
} else { //数据包未压缩
//包头有错误,立即关闭连接
if (header.originsize <= 0 || header.originsize > MAX_PACKAGE_SIZE) {
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
//收到的数据不够一个完整的包
if (pBuffer->readableBytes() < (size_t)header.originsize + sizeof(msg_header))
return;
pBuffer->retrieve(sizeof(msg_header));
std::string inbuf;
inbuf.append(pBuffer->peek(), header.originsize);
pBuffer->retrieve(header.originsize);
//业务逻辑处理
if (!Process(conn, inbuf.c_str(), inbuf.length())) {
//客户端发非法数据包,服务器主动关闭之
conn->forceClose();
return;
}
}// end else
}// end while-loop
}
这段代码先根据包头的压缩标志字段判断包体是否有压缩,如果有压缩,则取出包体大小去解压,解压后的数据才是真正的业务数据。整个程序执行流程图如下:
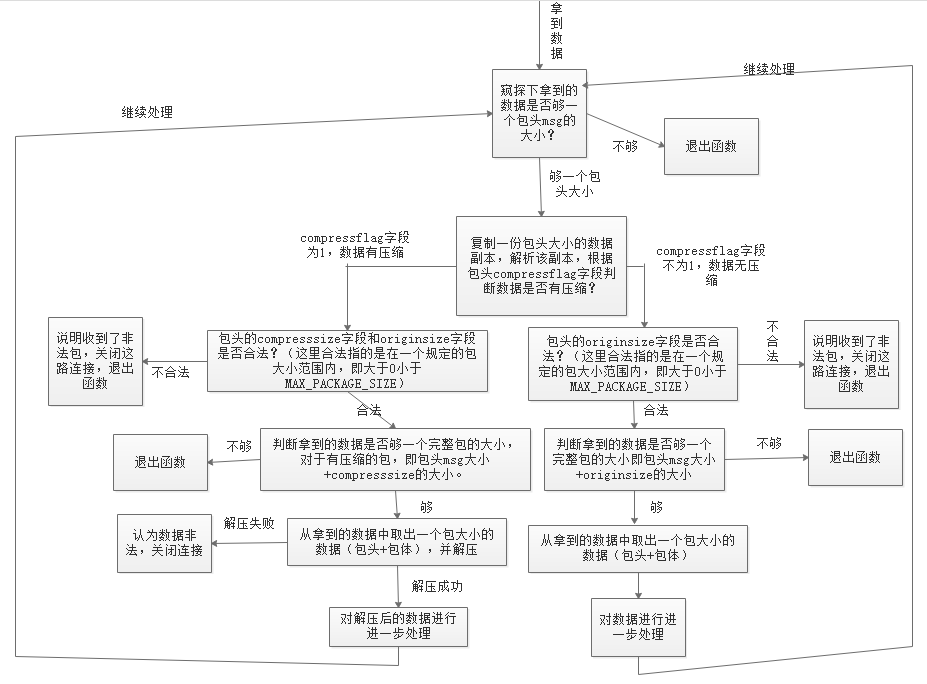
代码中有一个接收缓冲区变量 pBuffer,关于接收缓冲区如何设计,我们将在后面的章节中详细介绍。
从 struct 到 TLV——协议的演化历史
假设现在 A 与 B 之间要传输一个关于用户信息的数据包,可以将该数据包格式定义成如下形式:
#pragma pack(push, 1)
struct userinfo
{
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
};
#pragma pack(pop)
相信很多读者曾经都定义过这样的协议,这种数据结构简单明了,对端只要直接拷贝按字段解析就可以了。但是,需求总是不断变化的,某一天根据新的需求需要在这个结构中增加一个字段表示用户的年龄,于是修改协议结构成:
#pragma pack(push, 1)
struct userinfo
{
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
//用户年龄
int32_t age;
};
#pragma pack(pop)
问题并没有直接增加一个字段那么简单,新修改的协议格式导致旧的客户端无法兼容(旧的客户端已经分发出去),这个时候我们升级服务器端的协议格式成新的,会导致旧的客户端无法使用。所以我们在最初设计协议的时候,我们需要增加一个版本号字段,针对不同的版本来做不同的处理,即:
/**
* 旧的协议,版本号是 1
*/
#pragma pack(push, 1)
struct userinfo
{
//版本号
short version;
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
};
#pragma pack(pop)
/**
* 新的协议,版本号是 2
*/
#pragma pack(push, 1)
struct userinfo
{
//版本号
short version;
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
//用户年龄
int32_t age;
};
#pragma pack(pop)
这样我们可以用以下伪码来兼容新旧协议:
//从包中读取一个 short 型字段
short version = <从包中读取一个 short 型字段>;
if (version == 1)
{
//当旧的协议格式进行处理
}
else if (version == 2)
{
//当新的协议格式进行处理
}
上述方法是一个兼容旧版协议的常见做法。但是这样也存在一个问题,如果我们的业务需求变化快,我们可能需要经常调整协议字段(增、删、改),这样我们的版本号数量会比较多,我们的代码会变成类似下面这种形式:
//从包中读取一个 short 型字段
short version = <从包中读取一个 short 型字段>;
if (version == 版本号1)
{
//对版本号1格式进行处理
}
else if (version == 版本号2)
{
//对版本号2格式进行处理
}
else if (version == 版本号3)
{
//对版本号3格式进行处理
}
else if (version == 版本号4)
{
//对版本号4格式进行处理
}
else if (version == 版本号5)
{
//对版本号5格式进行处理
}
...省略更多...
这只是仅考虑了协议顶层结构还没有考虑更多复杂的嵌套结构,这样的代码会变得越来越难以维护。
这里只是为了说明问题,实际开发中,建议读者在设计协议时尽量考虑周全,避免反复修改协议结构。
上述协议格式还存在另外一个问题,对于 name 字段,其长度为 8 个字节,这种定长的字段,长度大小不具有伸缩性,太长很多情况都用不完则造成内存和网络带宽的浪费,太短则某些情况下不够用。那么有没有什么方法来解决呢?
方法是有的,对于字符串类型的字段,我们可以在该字段前面加一个表示字符串长度(length)的标志,那么上面的协议在内存中的状态可以表示成如下图示:

这种方法解决了定义字符串类型的太长浪费太短不够用的问题,但是没有解决修改协议(如新增字段)需要兼容众多旧版本问题,对于这个问题,我们可以通过在每个字段前面加一个 type 类型也解决,我们可以使用一个 char 类型来表示常用的类型,规定如下:
| 类型 | Type值 | 类型描述 |
|---|---|---|
| bool | 0 | 布尔值 |
| char | 1 | char 型 |
| int16 | 2 | 16 位整型 |
| int32 | 3 | 32 位整型 |
| int64 | 4 | 64 位整形 |
| string | 5 | 字符串或二进制序列 |
| ... |
那么对于上述协议,其内存格式变成:

这样,每个字段的类型就是自解释了。这就是所谓的 TLV(Type-Length-Value)格式。这种格式的协议,我们可以方便地增删和修改字段类型,程序解析时根据每个字段的 type 来得到字段的类型。
这里再根据笔者的经验多说几句,实际开发中 TLV 类型虽然易于扩展,但是也存在如下缺点:
-
TLV 格式因为每个字段增加了一个 type 类型,导致所占空间增大;
-
我们在解析字段时需要额外增加一些判断 type 的逻辑,去判断字段的类型,做相应的处理,即:
//读取第一个字节得到 type
if (type == Type::BOOL)
{
//bool型处理
}
else if (type == Type::CHAR)
{
//char型处理
}
else if (type == Type::SHORT)
{
//short型处理
}
...更多类型省略...如上代码所示,每个字段我们都需要有这样的逻辑判断,这样的编码方式是非要麻烦的。
-
即使我们知道了每个字段的技术类型(相对业务来说),每个字段的业务含义仍然需要我们制定文档格式,也就是说 TLV 格式只是做到了技术上自解释。
所以,在实际的开发中,完全遵循 TLV 格式的协议并不多,尤其是针对一些整型类型的字段。
在 TLV 格式的基础上还扩展了一种叫 TTLV 格式的协议,即 Tag-Type-Length-Value,每个字段前面在增加一个 Tag 类型,Tag 的含义由协议双方协定好。
协议设计工具
虽然 TLV 很简单,每搞一套新的协议,都要从头编解码、调试,但是写编解码是一个毫无技术含量的枯燥体力活。在大量复制粘贴过程中,非常容易出错。
因此出现了一种叫 IDL(Interface Description Language)的语言规范,它是一种描述语言,也是一个中间语言,IDL 规范协议的使用类型,提供跨语言特性。可以定义一个描述协议格式的 IDL 文件,然后通过 IDL 工具分析 IDL 文件,�就可以生成各种语言版本的协议代码。Google Protobuf 库自带的工具 protoc 就是这样一个工具。
通信协议设计时的注意事项
通过前面的章节的讨论,相信读者应该对协议设计有一定的了解了。本节我们来讨论一下协议设计时的一些注意事项。
字节对齐
留心的读者一定注意到,前面讨论的协议示例中:
#pragma pack(push, 1)
struct userinfo
{
//版本号
short version;
//命令号
int32_t cmd;
//用户性别
char gender;
//用户昵称
char name[8];
//用户年龄
int32_t age;
};
#pragma pack(pop)
有一组成对的 #pragma XX 指令,其中 #pragma pack(push, n),是告诉编译器接下来的所有结构体(这里就是 userinfo 协议)的每一个字段按 n 个字节对齐,这里 n = 1,按一个字节对齐,即去除任何 padding 字节。这样做的目的是为了内存更加紧凑,节省存储空间。
我们不再需要这个对齐功能后,应该使用 #pragma pack(pop) 让编译器恢复默认的对齐方式。
注意:#pragma pack(push, n) 与 #pragma pack(pop) 一定要成对使用,如果你漏掉其中任何一个,编译出来的代码可能会出现很多奇怪的运行结果。
显式指定整型字段的长度
对于一个 int 型字段,在作为协议传输时,我们应该显式地指定该类型的长度,也就是说,你应该使用 int32_t、int64_t 这样的类型来代替 int、long。之所以这么做的原因是,对于不同字长的机器,对于默认的 int 和 long 的长度可能不一样,例如 long 型,在 32 位操作系统上其长度是 4 个字节,而在 64 位机器上其长度是 8 个字节。如果不显式指定这种整形的长度,可能因为不同机器字长不同,导致协议解析出错或者产生错误的结果。
涉及到浮点数要考虑精度问题,建议放大成整数或者使用字符串去传输
由于计算机表示浮点数存在精度取舍不准确的问题,例如对于 1.000000,有的计算机可能会得到 0.999999,在某些应用中,如果这个浮点数的业务单位比较大(如表示金额,单位为亿),就会造成很大的影响。因此为了避免不同的机器解析得到不同的结果,建议在网络传输时将浮点数值放大相应的倍数变成整数或者转换为字符串来进行传输。
大小端编码问题
在第四章我们已经详细地介绍大小端的问题(即主机字节序和网络字节序),在设计协议格式时,如果协议中存在整型字段,建议使用同一个字节序。通常的做法是在进行网络传输时将所有的整型转换为网络字节序(大段编码,Big Endian),避免不同的机器因为大小端问题解析得到不同的整型值。
当然,不一定非要转换为网络字节序,如果明确的知道通信的双方使用的是相同的字节序,则也可以不转换。
协议的分类
根据协议的内容是否是文本格式(即人为可读格式),我们将协议分为文本协议和二进制协议,像 http 协议的包头部分和 FTP 协议等都是典型的文本协议的例子。
协议与自动升级功能
对于一个商业的产品,发布出去的客户端一般通过客户端的自动升级功能去获得更新(IOS App 除外,苹果公司要求所有的 App 必须在其 App Store 上更新新版本,禁止热更新)。在客户端与服务器通信的所有协议格式中,自动升级协议是最重要的一个,无论版本如何迭代,一定要保证自动升级协议的新旧兼容,这样做有如下原因:
- 如果新的服务器不能兼容旧客户端中的自动升级协议,那么旧的客户端用户将无法升级成新的版本了,这样的产品相当于把自己给“阉割”了。对于不少产品,不通过自动升级而让众多用户去官网下载新的版本是一件很难做到的事情,这种决策可能会导致大量用户流失;
- 退一步讲,对于一些测试不完善,或者处于快速迭代中的产品,只要保证自动升级功能正常,旧版本任何 bug 和瑕疵都可以通过升级新版本解决。这对于一些想投放市场试水,但又可能设计不充分的产品尤其重要。
顺便提一下,一般自动升级功能是根据当前版本的版本号与服务器端新版本的版本号进行比较,如果二者之间存在一个大版本号的差别(如1.0.0 与 2.0.0)�,即有重大功能更新,则应该强制客户端更新下载最新版本;如果只是一个小版本号的更新(如 1.0.0 与 1.1.0),则可以让用户选择是否更新。当然,如果是新版本修正了前一个版本中严重影响使用的 bug,也应答强制用户更新。
协议实例:WebSocket 协议
WebSocket 协议是为了解决 http 协议的无状态、短连接(通常是)和服务端无法主动给客户端推送数据等问题而开发的新型协议,其通信基础也是基于 TCP。由于较旧的浏览器可能不支持 WebSocket 协议,所以使用 WebSocket 协议的通信双方在进行 TCP 三次握手之后,还要再额外地进行一次握手,这一次的握手通信双方的报文格式是基于 HTTP 协议改造的。
WebSocket 握手过程
TCP 三次握手的过程我们就不在这里赘述了,任何一本网络通信书籍上都有详细的介绍。我们这里来介绍一下 WebSocket 通信最后一次的握手过程。
握手开始后,一方给另外一方发送一个 http 协议格式的报文,这个报文格式大致如下:
GET /realtime HTTP/1.1\r\n
Host: 127.0.0.1:9989\r\n
Connection: Upgrade\r\n
Pragma: no-cache\r\n
Cache-Control: no-cache\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)\r\n
Upgrade: websocket\r\n
Origin: http://xyz.com\r\n
Sec-WebSocket-Version: 13\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
Sec-WebSocket-Key: IqcAWodjyPDJuhGgZwkpKg==\r\n
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits\r\n
\r\n
对这个格式有如下要求:
- 握手必须是一个有效的 HTTP 请求;
- 请求的方法必须为 GET,且 HTTP 版本必须是 1.1;
- 请求必须包含 Host 字段信息;
- 请求必须包含 Upgrade字段信息,值必须为 websocket;
- 请求必须包含 Connection 字段信息,值必须为 Upgrade;
- 请求必须包含 Sec-WebSocket-Key 字段,该字段值是客户端的标识编码成 base64 格式;
- 请求必须包含 Sec-WebSocket-Version 字段信息,值必须为 13;
- 请求必须包含 Origin 字段;
- 请求可能包含 Sec-WebSocket-Protocol 字段,规定子协议;
- 请求可能包含 Sec-WebSocket-Extensions字段规定协议扩展;
- 请求可能包含其他字段,如 cookie 等。
对端收到该数据包后如果支持 WebSocket 协议,会回复一个 http 格式的应答,这个应答报文的格式大致如下:
HTTP/1.1 101 Switching Protocols\r\n
Upgrade: websocket\r\n
Connection: Upgrade\r\n
Sec-WebSocket-Accept: 5wC5L6joP6tl31zpj9OlCNv9Jy4=\r\n
\r\n
上面列出了应答报文中必须包含的几个字段和对应的值,即 Upgrade、Connection、Sec-WebSocket-Accept,注意:第一行必须是 HTTP/1.1 101 Switching Protocols\r\n。
对于字段 Sec-WebSocket-Accept 字段,其值是根据对端传过来的 Sec-WebSocket-Key 的值经过一定的算法计算出来的,这样应答的双方才能匹配。算法如下:
- 将 Sec-WebSocket-Key 值与固定字符串“258EAFA5-E914-47DA-95CA-C5AB0DC85B11” 进行拼接;
- 将拼接后的字符串进行 SHA-1 处理,然后将结果再进行 base64 编码。
算法公式:
mask = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11"; // 这是算法中要用到的固定字符串
accept = base64( sha1( Sec-WebSocket-Key + mask ) );
我用 C++ 实现了该算法:
namespace uWS {
struct WebSocketHandshake {
template <int N, typename T>
struct static_for {
void operator()(uint32_t *a, uint32_t *b) {
static_for<N - 1, T>()(a, b);
T::template f<N - 1>(a, b);
}
};
template <typename T>
struct static_for<0, T> {
void operator()(uint32_t *a, uint32_t *hash) {}
};
template <int state>
struct Sha1Loop {
static inline uint32_t rol(uint32_t value, size_t bits) {return (value << bits) | (value >> (32 - bits));}
static inline uint32_t blk(uint32_t b[16], size_t i) {
return rol(b[(i + 13) & 15] ^ b[(i + 8) & 15] ^ b[(i + 2) & 15] ^ b[i], 1);
}
template <int i>
static inline void f(uint32_t *a, uint32_t *b) {
switch (state) {
case 1:
a[i % 5] += ((a[(3 + i) % 5] & (a[(2 + i) % 5] ^ a[(1 + i) % 5])) ^ a[(1 + i) % 5]) + b[i] + 0x5a827999 + rol(a[(4 + i) % 5], 5);
a[(3 + i) % 5] = rol(a[(3 + i) % 5], 30);
break;
case 2:
b[i] = blk(b, i);
a[(1 + i) % 5] += ((a[(4 + i) % 5] & (a[(3 + i) % 5] ^ a[(2 + i) % 5])) ^ a[(2 + i) % 5]) + b[i] + 0x5a827999 + rol(a[(5 + i) % 5], 5);
a[(4 + i) % 5] = rol(a[(4 + i) % 5], 30);
break;
case 3:
b[(i + 4) % 16] = blk(b, (i + 4) % 16);
a[i % 5] += (a[(3 + i) % 5] ^ a[(2 + i) % 5] ^ a[(1 + i) % 5]) + b[(i + 4) % 16] + 0x6ed9eba1 + rol(a[(4 + i) % 5], 5);
a[(3 + i) % 5] = rol(a[(3 + i) % 5], 30);
break;
case 4:
b[(i + 8) % 16] = blk(b, (i + 8) % 16);
a[i % 5] += (((a[(3 + i) % 5] | a[(2 + i) % 5]) & a[(1 + i) % 5]) | (a[(3 + i) % 5] & a[(2 + i) % 5])) + b[(i + 8) % 16] + 0x8f1bbcdc + rol(a[(4 + i) % 5], 5);
a[(3 + i) % 5] = rol(a[(3 + i) % 5], 30);
break;
case 5:
b[(i + 12) % 16] = blk(b, (i + 12) % 16);
a[i % 5] += (a[(3 + i) % 5] ^ a[(2 + i) % 5] ^ a[(1 + i) % 5]) + b[(i + 12) % 16] + 0xca62c1d6 + rol(a[(4 + i) % 5], 5);
a[(3 + i) % 5] = rol(a[(3 + i) % 5], 30);
break;
case 6:
b[i] += a[4 - i];
}
}
};
/**
* sha1 函数的实现
*/
static inline void sha1(uint32_t hash[5], uint32_t b[16]) {
uint32_t a[5] = {hash[4], hash[3], hash[2], hash[1], hash[0]};
static_for<16, Sha1Loop<1>>()(a, b);
static_for<4, Sha1Loop<2>>()(a, b);
static_for<20, Sha1Loop<3>>()(a, b);
static_for<20, Sha1Loop<4>>()(a, b);
static_for<20, Sha1Loop<5>>()(a, b);
static_for<5, Sha1Loop<6>>()(a, hash);
}
/**
* base64 编码函数
*/
static inline void base64(unsigned char *src, char *dst) {
const char *b64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
for (int i = 0; i < 18; i += 3) {
*dst++ = b64[(src[i] >> 2) & 63];
*dst++ = b64[((src[i] & 3) << 4) | ((src[i + 1] & 240) >> 4)];
*dst++ = b64[((src[i + 1] & 15) << 2) | ((src[i + 2] & 192) >> 6)];
*dst++ = b64[src[i + 2] & 63];
}
*dst++ = b64[(src[18] >> 2) & 63];
*dst++ = b64[((src[18] & 3) << 4) | ((src[19] & 240) >> 4)];
*dst++ = b64[((src[19] & 15) << 2)];
*dst++ = '=';
}
public:
/**
* 生成 Sec-WebSocket-Accept 算法
* @param input 对端传过来的Sec-WebSocket-Key值
* @param output 存放生成的 Sec-WebSocket-Accept 值
*/
static inline void generate(const char input[24], char output[28]) {
uint32_t b_output[5] = {
0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476, 0xc3d2e1f0
};
uint32_t b_input[16] = {
0, 0, 0, 0, 0, 0, 0x32353845, 0x41464135, 0x2d453931, 0x342d3437, 0x44412d39,
0x3543412d, 0x43354142, 0x30444338, 0x35423131, 0x80000000
};
for (int i = 0; i < 6; i++) {
b_input[i] = (input[4 * i + 3] & 0xff) | (input[4 * i + 2] & 0xff) << 8 | (input[4 * i + 1] & 0xff) << 16 | (input[4 * i + 0] & 0xff) << 24;
}
sha1(b_output, b_input);
uint32_t last_b[16] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 480};
sha1(b_output, last_b);
for (int i = 0; i < 5; i++) {
uint32_t tmp = b_output[i];
char *bytes = (char *) &b_output[i];
bytes[3] = tmp & 0xff;
bytes[2] = (tmp >> 8) & 0xff;
bytes[1] = (tmp >> 16) & 0xff;
bytes[0] = (tmp >> 24) & 0xff;
}
base64((unsigned char *) b_output, output);
}
};
握手完成之后,通信双方就可以保持连接并相互发送数据了。
WebSocket 协议格式
WebSocket 协议格式的 RFC 文档可以参见:https://tools.ietf.org/html/rfc6455。
常听人说 WebSocket 协议是基于 http 协议的,因此我在刚接触 WebSocket 协议时总以为每个 WebSocket 数据包都是 http 格式,其实不然,WebSocket 协议除了上文中提到的这次握手过程中使用的数据格式是 http 协议格式,之后的通信双方使用的是另外一种自定义格式。每一个 WebSocket 数据包我们称之为一个 Frame(帧),其格式图如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
我们来逐一介绍一下上文中各字段的含义:
第一个字节内容:
-
FIN 标志,占第一个字节中的第一位(bit),即一字节中的最高位(一字节等于 8 位),该标志置 0 时表示当前包未结束后续有该包的分片,置 1 时表示当前包已结束后续无该包的分片。我们在解包时,如果发现该标志为 0,则需要将当前包的“包体”数据(即图中 Payload Data)缓存起来,与后续包分片组装在一起,才是一个完整的包体数据。
-
RSV1、RSV2、RSV3 每个占一位,一共三位,这三个位是保留字段(默认都是 0),你可以用它们作为通信的双方协商好的一些特殊标志;
-
opCode 操作类型,占四位,目前操作类型及其取值如下:
// 4 bits
enum OpCode
{
//表示后续还有新的 Frame
CONTINUATION_FRAME = 0x0,
//包体是文本类型的Frame
TEXT_FRAME = 0x1,
//包体是二进制类型的 Frame
BINARY_FRAME = 0x2,
//保留值
RESERVED1 = 0x3,
RESERVED2 = 0x4,
RESERVED3 = 0x5,
RESERVED4 = 0x6,
RESERVED5 = 0x7,
//建议对端关闭的 Frame
CLOSE = 0x8,
//心跳包中的 ping Frame
PING = 0x9,
//心跳包中的 pong Frame
PONG = 0xA,
//保留值
RESERVED6 = 0xB,
RESERVED7 = 0xC,
RESERVED8 = 0xD,
RESERVED9 = 0xE,
RESERVED10 = 0xF
};
第二个字节内容:
-
mask 标志,占一位,该标志为 1 时,表明该 Frame 在包体长度字段后面携带 4 个字节的 masking-key 信息,为 0 时则没有 masking-key 信息。masking-key 信息下文会介绍。
-
Payload len,占七位,该字段表示包体的长度信息。由于 Payload length 值使用了一个字节的低七位(7 bit),因此其能表示的长度范围是 0 ~ 127,其中 126 和 127 被当做特殊标志使用。
当该字段值是 0~125 时,表示跟在 masking-key 字段后面的就是包体内容长度;当该值是 126 时,接下来的 2 个字节内容表示跟在 masking-key 字段后面的包体内容的长度(即图中的 Extended Payload Length)。由于 2 个字节最大表示的无符号整数是 0xFFFF(十进制是 65535, 编译器提供了一个宏 UINT16_MAX 来表示这个值)。如果包体长度超过 65535,包长度就记录不下了,此时应该将 Payload length 设置为 127,以使用更多的字节数来表示包体长度。
当 Payload length 是 127 时,接下来则用 8 个字节内容表示跟在 masking-key 字段后面的包体内容的长度(Extended Payload Length)。
总结起来,Payload length = 0 ~ 125,Extended Payload Length 不存在, 0 字节;Payload length = 126, Extended Payload Length 占 2 字节;Payload length = 127 时,Extended Payload Length 占 8 字节。
另外需要注意的是,当 Payload length = 125 或 126 时接下来存储实际包长的 2 字节或 8 字节,其值必须转换为网络字节序(Big Endian)。
-
Masking-key ,如果前面的 mask 标志设置成 1,则该字段存在,占 4 个字节;反之,则 Frame 中不存在存储 masking-key 字段的字节。
网络上一些资料说,客户端(主动发起握手请求的一方)给服务器(被动接受握手的另一方)发的 frame 信息(包信息),mask 标志必须是 1,而服务器给客户端发送的 frame 信息中 mask 标志是 0。因此,客户端发给服务器端的数据帧中存在 4 字节的 masking-key,而服务器端发给客户端的数据帧中不存在 masking-key 信息。
我在 Websocket 协议的 RFC 文档中并没有看到有这种强行规定,另外在研究了一些 websocket 库的实现后发现,此结论并不一定成立,客户端发送的数据也可能没有设置 mask 标志。
如果存在 masking-key 信息,则数据帧中的数据(图中 Payload Data)都是经过与 masking-key 进行运算后的内容。无论是将原始数据与 masking-key 运算后得到传输的数据,还是将传输的数据还原成原始数据,其算法都是一样的。算法如下:
假设:
original-octet-i:为原始数据的第 i 字节。
transformed-octet-i:为转换后的数据的第 i 字节。
j:为i mod 4的结果。
masking-key-octet-j:为 mask key 第 j 字节。算法描述为: original-octet-i 与 masking-key-octet-j 异或后,得到 transformed-octet-i。
j = i MOD 4
transformed-octet-i = original-octet-i XOR masking-key-octet-j我用 C++ 实现了该算法:
/**
* @param src 函数调用前是原始需要传输的数据,函数调用后是mask或者unmask后的内容
* @param maskingKey 四字节
*/
void maskAndUnmaskData(std::string& src, const char* maskingKey)
{
char j;
for (size_t n = 0; n < src.length(); ++n)
{
j = n % 4;
src[n] = src[n] ^ maskingKey[j];
}
}使用上面的描述可能还不是太清楚,我们举个例子,假设有一个客户端发送给服务器的数据包,那么 mask = 1,即存在 4 字节的 masking-key,当包体数据长度在 0 ~ 125 之间时,该包的结构:
第 1 个字节第 0 位 => FIN
第 1 个字节第 1 ~ 3位 => RSV1 + RSV2 + RSV3
第 1 个字节第 4 ~ 7位 => opcode
第 2 个字节第 0 位 => mask(等于 1)
第 2 个字节第 1 ~ 7位 => 包体长度
第 3 ~ 6 个字节 => masking-key
�第 7 个字节及以后 => 包体内容这种情形,包头总共 6 个字节。
当包体数据长度大于125 且小于等于 UINT16_MAX 时,该包的结构:
第 1 个字节第 0 位 => FIN
第 1 个字节第 1 ~ 3位 => RSV1 + RSV2 + RSV3
第 1 个字节第 4 ~ 7位 => opcode
第 2 个字节第 0 位 => mask(等于 1)
第 2 个字节第 1 ~ 7位 => 开启扩展包头长度标志,值为 126
第 3 ~ 4 个字节 => 包头长度
第 5 ~ 8 个字节 => masking-key
第 9 个字节及以后 => 包体内容这种情形,包头总共 8 个字节。
当包体数据长度大于 UINT16_MAX 时,该包的结构:
第 1 个字节第 0 位 => FIN
第 1 个字节第 1 ~ 3位 => RSV1 + RSV2 + RSV3
第 1 个字节第 4 ~ 7位 => opcode
第 2 个字节第 0 位 => mask(等于 1)
第 2 个字节第 1 ~ 7位 => 开启扩展包头长度标志,值为 127
第 3 ~ 10 个字节 => 包头长度
第 11 ~ 14 个字节 => masking-key
第 15 个字节及以后 => 包体内容这种情形,包头总共 14 个字节。由于存储包体长度使用 8 字节存储(无符号),因此最大包体长度是 0xFFFFFFFFFFFFFFFF,这是一个非常大的数字,但实际开发中,我们用不到这么长的包体,且当包体超过一定值时,我们就应该分包(分片)了。
分包的逻辑经过前面的分析也很简单,假设将一个包分成 3 片,那么应将第一个和第二个包片的第一个字节的第一位 FIN 设置为 0,OpCode 设置为 CONTINUATION_FRAME(也是 0);第三个包片 FIN 设置为 1,表示该包至此就结束了,OpCode 设置为想要的类型(如 TEXT_FRAME、BINARY_FRAME 等)。对端收到该包时,如果发现标志 FIN = 0 或 OpCode = 0,将该包包体的数据暂存起来,直到收到 FIN = 1,OpCode ≠ 0 的包,将该包的数据与前面收到的数据放在一起,组装成一个完整的业务数据。示例代码如下:
//某次解包后得到包体 payloadData,根据 FIN 标志判断,
//如果 FIN = true,则说明一个完整的业务数据包已经收完整,
//调用 processPackage() 函数处理该业务数据
//否则,暂存于 m_strParsedData 中
//每次处理完一个完整的业务包数据,即将暂存区m_strParsedData中的数据清空
if (FIN)
{
m_strParsedData.append(payloadData);
processPackage(m_strParsedData);
m_strParsedData.clear();
}
else
{
m_strParsedData.append(payloadData);
}WebSocket 压缩格式
WebSocket 对于包体也支持压缩的,是否需要开启压缩需要通信双方在握手时进行协商。让我们再看一下握手时主动发起一方的包内容:
GET /realtime HTTP/1.1\r\n
Host: 127.0.0.1:9989\r\n
Connection: Upgrade\r\n
Pragma: no-cache\r\n
Cache-Control: no-cache\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)\r\n
Upgrade: websocket\r\n
Origin: http://xyz.com\r\n
Sec-WebSocket-Version: 13\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8\r\n
Sec-WebSocket-Key: IqcAWodjyPDJuhGgZwkpKg==\r\n
Sec-WebSocket-Extensions: permessage-deflate; client_max_window_bits\r\n
\r\n在该包中 Sec-WebSocket-Extensions 字段中有一个值 permessage-deflate,如果发起方支持压缩,在发起握手时将包中带有该标志,对端收到后,如果也支持压缩,则在应答的包也带有该字段,反之不带该标志即表示不支持压缩。例如:
HTTP/1.1 101 Switching Protocols\r\n
Upgrade: websocket\r\n
Connection: Upgrade\r\n
Sec-WebSocket-Accept: 5wC5L6joP6tl31zpj9OlCNv9Jy4=\r\n
Sec-WebSocket-Extensions: permessage-deflate; client_no_context_takeover
\r\n如果双方都支持压缩,此后通信的包中的包体部分都是经过压缩后的,反之是未压缩过的。在解完包得到包体(即 Payload Data) 后,如果有握手时有压缩标志并且乙方也回复了支持压缩,则需要对该包体进行解压;同理,在发数据组装 WebSocket 包时,需要先将包体(即 Payload Data)进行压缩。
收到包需要解压示例代码:
bool MyWebSocketSession::processPackage(const std::string& data)
{
std::string out;
//m_bClientCompressed在握手确定是否支持压缩
if (m_bClientCompressed)
{
//解压
if (!ZlibUtil::inflate(data, out))
{
LOGE("uncompress failed, dataLength: %d", data.length());
return false;
}
}
else
out = data;
//如果不需要解压,则out=data,反之则out是解压后的数据
LOGI("receid data: %s", out.c_str());
return Process(out);
}对包进行压缩的算法:
size_t dataLength = data.length();
std::string destbuf;
if (m_bClientCompressed) {
//按需压缩
if (!ZlibUtil::deflate(data, destbuf)) {
LOGE("compress buf error, data: %s", data.c_str());
return;
}
} else
destbuf = data;
LOGI("destbuf.length(): %d", destbuf.length());压缩和解压算法即 gzip 压缩算法。
压缩和解压的函数我使用 zlib 库的 deflate 和 inflate 函数实现了如下:
/**
* gzip压缩算法
* @param strSrc 压缩前的字符串
* @param strDest 压缩后的字符串
*/
bool ZlibUtil::deflate(const std::string& strSrc, std::string& strDest)
{
int err = Z_DATA_ERROR;
// Create stream
z_stream zS = { 0 };
// Set output data streams, do this here to avoid overwriting on recursive calls
const int OUTPUT_BUF_SIZE = 8192;
Bytef bytesOut[OUTPUT_BUF_SIZE] = { 0 };
// Initialise the z_stream
err = ::deflateInit2(&zS, 1, Z_DEFLATED, -15, 8, Z_DEFAULT_STRATEGY);
if (err != Z_OK)
{
return false;
}
// Use whatever input is provided
zS.next_in = (Bytef*)(strSrc.c_str());
zS.avail_in = strSrc.length();
do {
try
{
// Initialise stream values
//zS->zalloc = (alloc_func)0;
//zS->zfree = (free_func)0;
//zS->opaque = (voidpf)0;
zS.next_out = bytesOut;
zS.avail_out = OUTPUT_BUF_SIZE;
// Try to unzip the data
err = ::deflate(&zS, Z_SYNC_FLUSH);
// Is zip finished reading all currently available input and writing all generated output
if (err == Z_STREAM_END)
{
// Finish up
int kerr = ::deflateEnd(&zS);
//不关心返回结果
//if (err != Z_OK)
//{
// //TRACE_UNZIP("; Error: end stream failed: %d\n", err);
// return false;
//}
// Got a good result, set the size to the amount unzipped in this call (including all recursive calls)
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
return true;
}
else if ((err == Z_OK) && (zS.avail_out == 0) && (zS.avail_in != 0))
{
// Output array was not big enough, call recursively until there is enough space
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
continue;
}
else if ((err == Z_OK) && (zS.avail_in == 0))
{
// All available input has been processed, everything ok.
// Set the size to the amount unzipped in this call (including all recursive calls)
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
int kerr = ::deflateEnd(&zS);
//不关心结果
//if (err != Z_OK)
//{
// //TRACE_UNZIP("; Error: end stream failed: %d\n", err);
// return false;
//}
break;
}
else
{
return false;
}
}
catch (...)
{
return false;
}
} while (true);
if (err == Z_OK)
{
//减去4是为了去掉deflat函数加在末尾多余的00 00 ff ff
strDest = strDest.substr(0, strDest.length() - 4);
return true;
}
return false;
}
/**
* gzip解压算法
* @param strSrc 压缩前的字符串
* @param strDest 压缩后的字符串
*/
bool ZlibUtil::inflate(const std::string& strSrc, std::string& strDest)
{
int err = Z_DATA_ERROR;
// Create stream
z_stream zS = { 0 };
// Set output data streams, do this here to avoid overwriting on recursive calls
const int OUTPUT_BUF_SIZE = 8192;
Bytef bytesOut[OUTPUT_BUF_SIZE] = { 0 };
// Initialise the z_stream
err = ::inflateInit2(&zS, -15);
if (err != Z_OK)
{
return false;
}
// Use whatever input is provided
zS.next_in = (Bytef*)(strSrc.c_str());
zS.avail_in = strSrc.length();
do {
try
{
// Initialise stream values
//zS->zalloc = (alloc_func)0;
//zS->zfree = (free_func)0;
//zS->opaque = (voidpf)0;
zS.next_out = bytesOut;
zS.avail_out = OUTPUT_BUF_SIZE;
// Try to unzip the data
err = ::inflate(&zS, Z_SYNC_FLUSH);
// Is zip finished reading all currently available input and writing all generated output
if (err == Z_STREAM_END)
{
// Finish up
int kerr = ::inflateEnd(&zS);
//不关心返回结果
//if (err != Z_OK)
//{
// //TRACE_UNZIP("; Error: end stream failed: %d\n", err);
// return false;
//}
// Got a good result, set the size to the amount unzipped in this call (including all recursive calls)
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
return true;
}
else if ((err == Z_OK) && (zS.avail_out == 0) && (zS.avail_in != 0))
{
// Output array was not big enough, call recursively until there is
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
continue;
}
else if ((err == Z_OK) && (zS.avail_in == 0))
{
// All available input has been processed, everything ok.
// Set the size to the amount unzipped in this call (including all recursive calls)
strDest.append((const char*)bytesOut, OUTPUT_BUF_SIZE - zS.avail_out);
int kerr = ::inflateEnd(&zS);
//不关心结果
//if (err != Z_OK)
//{
// //TRACE_UNZIP("; Error: end stream failed: %d\n", err);
// return false;
//}
break;
}
else
{
return false;
}
}
catch (...)
{
return false;
}
} while (true);
return err == Z_OK;
}需要注意的是,在使用 zlib 的 deflate 函数进行压缩时,压缩完毕后要将压缩后的字节流末尾多余的 4 个字节删掉,这是因为 deflate 函数在压缩后会将内容为 00 00 ff ff 的特殊标志放入压缩后的缓冲区中去,这个标志不是我们需要的正文内容。
如果你分不清楚 deflate 和 inflate 哪个是压缩哪个是解压,可以这么记忆:deflate 原意是给轮胎放气,即压缩,inflate 是给轮胎充气,即解压,in 有放入的意思,带 in 的单词是解压,不带 in 的单词是压缩。
WebSocket 装包和解包示例代码
这里以服务器端发送给客户端的装包代码为例,根据上文所述,服务器端发包时不需要设置 mask 标志,因此包中不需要填充 4 字节的 masking-key,因此也不需要对包体内容进行 mask 运算。注意以下代码我没有为大包进行分片。
void MyWebSocketSession::send(const std::string& data, int32_t opcode/* = MyOpCode::TEXT_FRAME*/, bool compress/* = false*/)
{
//data是待发送的业务数据
size_t dataLength = data.length();
std::string destbuf;
//按需压缩
if (m_bClientCompressed && dataLength > 0)
{
if (!ZlibUtil::deflate(data, destbuf))
{
LOGE("compress buf error, data: %s", data.c_str());
return;
}
}
else
destbuf = data;
LOGI("destbuf.length(): %d", destbuf.length());
dataLength = destbuf.length();
char firstTwoBytes[2] = { 0 };
//设置分片标志FIN
firstTwoBytes[0] |= 0x80;
//设置opcode
firstTwoBytes[0] |= opcode;
const char compressFlag = 0x40;
if (m_bClientCompressed)
firstTwoBytes[0] |= compressFlag;
//mask = 0;
//实际发送的数据包
std::string actualSendData;
//包体长度小于 126 不使用扩展的包体长度字节
if (dataLength < 126)
{
firstTwoBytes[1] = dataLength;
actualSendData.append(firstTwoBytes, 2);
}
//包体长度大于等于 126 且小于 UINT16_MAX 使用 2 字节的扩展包体长度
else if (dataLength <= UINT16_MAX) //2字节无符号整数最大数值(65535)
{
firstTwoBytes[1] = 126;
char extendedPlayloadLength[2] = { 0 };
//转换为网络字节序
uint16_t tmp = ::htons(dataLength);
memcpy(&extendedPlayloadLength, &tmp, 2);
actualSendData.append(firstTwoBytes, 2);
actualSendData.append(extendedPlayloadLength, 2);
}
//包体长度大于 UINT16_MAX 使用 8 字节的扩展包体长度
else
{
firstTwoBytes[1] = 127;
char extendedPlayloadLength[8] = { 0 };
//转换为网络字节序
uint64_t tmp = ::htonll((uint64_t)dataLength);
memcpy(&extendedPlayloadLength, &tmp, 8);
actualSendData.append(firstTwoBytes, 2);
actualSendData.append(extendedPlayloadLength, 8);
}
//actualSendData是实际组包后的内容
actualSendData.append(destbuf);
//发送到网络上去
sendPackage(actualSendData.c_str(), actualSendData.length());
}
服务器收到客户端的数据包时,解包过程就稍微有一点复杂,根据客户端传送过来的数据包是否设置了 mask 标志,决定是否必须取出 4 字节的 masking-key,然后使用它们对包体内容进行还原,得到包体后我们还需要根据是否有压缩标志进行解压,再根据 FIN 标志把包体数据当做一个完整的业务数据还是先暂存起来等收完整后再处理。
bool MyWebSocketSession::decodePackage(Buffer* pBuffer, const std::shared_ptr<TcpConnection>& conn)
{
//readableBytesCount是当前收到的数据长度
size_t readableBytesCount = pBuffer->readableBytes();
const int32_t TWO_FLAG_BYTES = 2;
//最大包头长度
const int32_t MAX_HEADER_LENGTH = 14;
char pBytes[MAX_HEADER_LENGTH] = {0};
//已经收到的数据大于最大包长时仅拷贝可能是包头的最大部分
if (readableBytesCount > MAX_HEADER_LENGTH)
memcpy(pBytes, pBuffer->peek(), MAX_HEADER_LENGTH * sizeof(char));
else
memcpy(pBytes, pBuffer->peek(), readableBytesCount * sizeof(char));
//检测是否有FIN标志
bool FIN = (pBytes[0] & 0x80);
//TODO: 这里就不校验了,因为服务器和未知的客户端之间无约定
//bool RSV1, RSV2, RSV3;
//取第一个字节的低4位获取数据类型
int32_t opcode = (int32_t)(pBytes[0] & 0xF);
//取第二个字节的最高位,理论上说客户端发给服务器的这个字段必须设置为1
bool mask = ((pBytes[1] & 0x80));
int32_t headerSize = 0;
int64_t bodyLength = 0;
//按mask标志加上四个字节的masking-key长度
if (mask)
headerSize += 4;
//取第二个字节的低七位,即得到payload length
int32_t payloadLength = (int32_t)(pBytes[1] & 0x7F);
if (payloadLength <= 0 && payloadLength > 127)
{
LOGE("invalid payload length, payloadLength: %d, client: %s", payloadLength, conn->peerAddress().toIpPort().c_str());
return false;
}
if (payloadLength > 0 && payloadLength <= 125)
{
headerSize += TWO_FLAG_BYTES;
bodyLength = payloadLength;
}
else if (payloadLength == 126)
{
headerSize += TWO_FLAG_BYTES;
headerSize += sizeof(short);
if ((int32_t)readableBytesCount < headerSize)
return true;
short tmp;
memcpy(&tmp, &pBytes[2], 2);
int32_t extendedPayloadLength = ::ntohs(tmp);
bodyLength = extendedPayloadLength;
//包体长度不符合要求
if (bodyLength < 126 || bodyLength > UINT16_MAX)
{
LOGE("illegal extendedPayloadLength, extendedPayloadLength: %d, client: %s", bodyLength, conn->peerAddress().toIpPort().c_str());
return false;
}
}
else if (payloadLength == 127)
{
headerSize += TWO_FLAG_BYTES;
headerSize += sizeof(uint64_t);
//包长度不够
if ((int32_t)readableBytesCount < headerSize)
return true;
int64_t tmp;
memcpy(&tmp, &pBytes[2], 8);
int64_t extendedPayloadLength = ::ntohll(tmp);
bodyLength = extendedPayloadLength;
//包体长度不符合要求
if (bodyLength <= UINT16_MAX)
{
LOGE("illegal extendedPayloadLength, extendedPayloadLength: %lld, client: %s", bodyLength, conn->peerAddress().toIpPort().c_str());
return false;
}
}
if ((int32_t)readableBytesCount < headerSize + bodyLength)
return true;
//取出包头
pBuffer->retrieve(headerSize);
std::string payloadData(pBuffer->peek(), bodyLength);
//取出包体
pBuffer->retrieve(bodyLength);
if (mask)
{
char maskingKey[4] = { 0 };
//headerSize - 4即masking-key的位置
memcpy(maskingKey, pBytes + headerSize - 4, 4);
//对包体数据进行unmask还原
unmaskData(payloadData, maskingKey);
}
if (FIN)
{
//最后一个分片,与之前的合并(如果有的话)后处理
m_strParsedData.append(payloadData);
//包处理出错
if (!processPackage(m_strParsedData, (MyOpCode)opcode, conn))
return false;
m_strParsedData.clear();
}
else
{
//非最后一个分片,先缓存起来
m_strParsedData.append(payloadData);
}
return true;
}
解析握手协议示例代码
这里以服务器端处理客户端主动发过来的握手协议为准,代码中检测了上文中介绍的几个必需字段和值,同时获取客户端是否支持压缩的标志,如果所有检测都能通过则组装应答协议包,根据自己是否支持压缩带上压缩标志。
bool MyWebSocketSession::handleHandshake(const std::string& data, const std::shared_ptr<TcpConnection>& conn)
{
std::vector<std::string> vecHttpHeaders;
//按\r\n拆分成每一行
StringUtil::Split(data, vecHttpHeaders, "\r\n");
//至少有3行
if (vecHttpHeaders.size() < 3)
return false;
std::vector<std::string> v;
size_t vecLength = vecHttpHeaders.size();
for (size_t i = 0; i < vecLength; ++i)
{
//第一行获得参数名称和协议版本号
if (i == 0)
{
if (!parseHttpPath(vecHttpHeaders[i]))
return false;
}
else
{
//解析头标志
v.clear();
StringUtil::Cut(vecHttpHeaders[i], v, ":");
if (v.size() < 2)
return false;
StringUtil::trim(v[1]);
m_mapHttpHeaders[v[0]] = v[1];
}
}
//请求必须包含 Upgrade: websocket 头,值必须为 websocket
auto target = m_mapHttpHeaders.find("Connection");
if (target == m_mapHttpHeaders.end() || target->second != "Upgrade")
return false;
//请求必须包含 Connection: Upgrade 头,值必须为 Upgrade
target = m_mapHttpHeaders.find("Upgrade");
if (target == m_mapHttpHeaders.end() || target->second != "websocket")
return false;
//请求必须包含 Host 头
target = m_mapHttpHeaders.find("Host");
if (target == m_mapHttpHeaders.end() || target->second.empty())
return false;
请求必须包含 Origin 头
target = m_mapHttpHeaders.find("Origin");
if (target == m_mapHttpHeaders.end() || target->second.empty())
return false;
target = m_mapHttpHeaders.find("User-Agent");
if (target != m_mapHttpHeaders.end())
{
m_strUserAgent = target->second;
}
//检测是否支持压缩
target = m_mapHttpHeaders.find("Sec-WebSocket-Extensions");
if (target != m_mapHttpHeaders.end())
{
std::vector<std::string> vecExtensions;
StringUtil::Split(target->second, vecExtensions, ";");
for (const auto& iter : vecExtensions)
{
if (iter == "permessage-deflate")
{
m_bClientCompressed = true;
break;
}
}
}
target = m_mapHttpHeaders.find("Sec-WebSocket-Key");
if (target == m_mapHttpHeaders.end() || target->second.empty())
return false;
char secWebSocketAccept[29] = {};
balloon::WebSocketHandshake::generate(target->second.c_str(), secWebSocketAccept);
std::string response;
makeUpgradeResponse(secWebSocketAccept, response);
conn->send(response);
m_bUpdateToWebSocket = true;
return true;
}
bool MyWebSocketSession::parseHttpPath(const std::string& str)
{
std::vector<std::string> vecTags;
StringUtil::Split(str, vecTags, " ");
if (vecTags.size() != 3)
return false;
//TODO: 应该不区分大小写的比较
if (vecTags[0] != "GET")
return false;
std::vector<std::string> vecPathAndParams;
StringUtil::Split(vecTags[1], vecPathAndParams, "?");
//至少有一个路径参数
if (vecPathAndParams.empty())
return false;
m_strURL = vecPathAndParams[0];
if (vecPathAndParams.size() >= 2)
m_strParams = vecPathAndParams[1];
//WebSocket协议版本号必须1.1
if (vecTags[2] != "HTTP/1.1")
return false;
return true;
}
void MyWebSocketSession::makeGradeResponse(const char* secWebSocketAccept, std::string& response)
{
response = "HTTP/1.1 101 Switching Protocols\r\n"
"Content-Length: 0\r\n"
"Upgrade: websocket\r\n"
"Sec-Websocket-Accept: ";
response += secWebSocketAccept;
response +="\r\n"
"Server: WebsocketServer 1.0.0\r\n"
"Connection: Upgrade\r\n"
"Sec-WebSocket-Version: 13\r\n";
if (m_bClientCompressed)
response += "Sec-WebSocket-Extensions: permessage-deflate; client_no_context_takeover\r\n";
response += "Host: 127.0.0.1:9988\r\n";
//时间可以改成动态的
response +="Date: Wed, 21 Jun 2017 03:29:14 GMT\r\n"
"\r\n";
}