Web后端杂记
Nginx 必要知识
这里只会记录 Nginx 的必要知识点,在实际应用中,OpenResty 提供了更为友好和强大的功能,所以应当:
- 要尽可能少地配置
nginx.conf - 避免使用
if、set、rewrite等多个指令的配合 - 能通过 Lua 代码解决的,就别用 Nginx 的配置、变量和模块来解决。
这样可以最大限度地提高可读性、可维护性和可扩展性。
Nginx配置语法
Nginx 通过配置文件来控制自身行为,它的配置可以看作是一个简单的 DSL。Nginx 在进程启动的时候读取配置,并加载到内存中。如果修改了配置文件,需要你重启或者重载 Nginx,再次读取后才能生效。
worker_processes auto;
pid logs/nginx.pid;
error_log logs/error.log notice;
worker_rlimit_nofile 65535;
events {
worker_connections 16384;
}
http {
server {
listen 80;
listen 443 ssl;
location / {
proxy_pass https://foo.com;
}
}
}
stream {
server {
listen 53 udp;
}
}
每个指令都有自己适用的上下文(Context),也就是 NGINX 配置文件中指令的作用域。
最上层的是 main,里面是和具体业务无关的一些指令,比如上面出现的 worker_processes、pid 和 error_log,都属于 main 这个上下文。另外,上下文是有层级关系的,比如 location 的上下文是 server,server 的上下文是 http,http 的上下文是 main。
指令不能运行在错误的上下文中,NGINX 在启动时会检测 nginx.conf 是否合法。比如我们把 listen 80; 从 server 上下文换到 main 上下文,然后启动 NGINX 服务,会看到类似这样的报错:
"listen" directive is not allowed here ......
NGINX 不仅可以处理 HTTP 请求 和 HTTPS 流量,还可以处理 UDP 和 TCP 流量。
其中,七层的放在 HTTP 中,四层的放在 stream 中。在 OpenResty 里面, lua-nginx-module 和 stream-lua-nginx-module 分别和这俩对应
Nginx命令行
-? -h:帮助-c:使用指定的配置文件-g:指定配置指令-p:指定运行目录-s:发送信号stop:立刻停止服务quit:优雅的停止服务reload:在不停止服务的情况下,重载配置文件reopen:重新开始记录配置文件
-t -T:测试配置文件是否有语法错误-v -V:打印nginx的版本信息、编译信息等
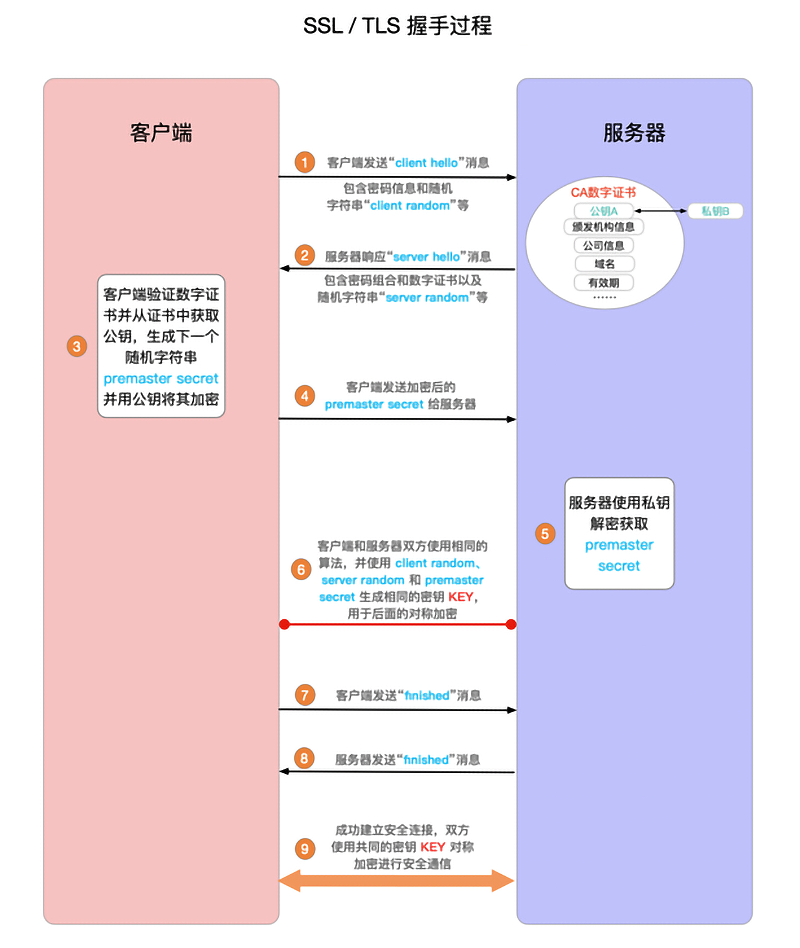
从网络原理来看SSL安全协议
-
TLS(Transport Layer Security)/SSL(Secure Sockets Layer)发展
SSL3.0(1995)→TLS1.0(1999) → TLS1.1(2006)→TLS1.2(2008)→TLS1.3(2018)
-
SSL/TLS通用模型

-
TLS安全密码套件
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
- ECDHE:密钥交换算法
- RSA:身份验证算法
- AES_128_GCM:对称加密算法、强度、分组模式
- SHA256:签名hash算法
-
对称加密
一份文档
document,Bob将该原始文档用密钥进行加密生成加密文档发送给Alice,那么Alice需要使用此密钥进行解密得到原始文档。以RC4加密算法为例,密钥
1010与明文0110进行异或,得到1100,1010⊕0110=1100,解密即1010⊕1100=0110 -
非对称加密
一份文档
document,Bob将该原始文档用Alice的公钥进行加密生成加密文档发送给Alice,那么Alice需要使��用自己的私钥进行解密得到原始文档。
SSL证书类型
-
域名验证(domain validated,DV)证书
-
组织验证(organization validated,OV)证书
-
扩展验证(extended validation,EV)证书
-
TLS通讯过程
验证身份→达成安全套件共识→传递密钥→加密通讯
处理HTTP请求头部的流程
接收请求事件模块
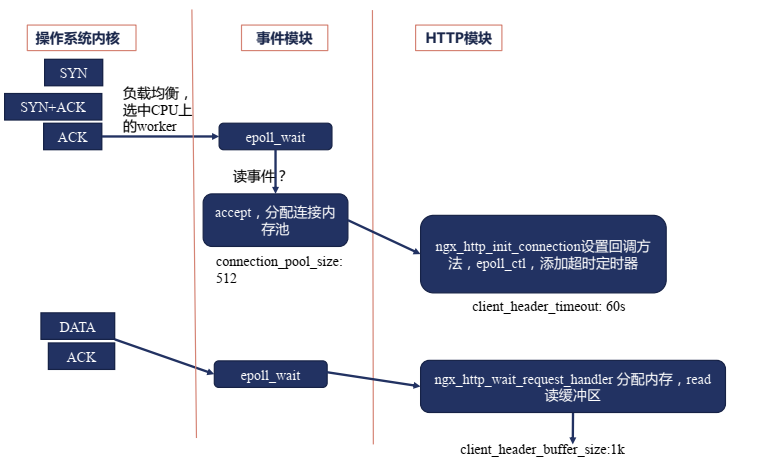
接收请求HTTP模块
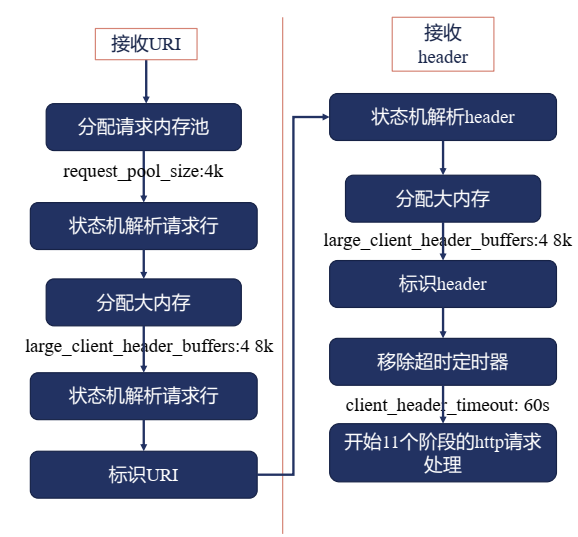
过大的请求头部
Syntax: client_header_buffer_size size;
Default:
client_header_buffer_size 1k;
Context: http, server
Syntax: large_client_header_buffers number size;
Default:
large_client_header_buffers 4 8k;
Context: http, server
如何找到匹配的server指令块
server_name指令,指令后可以跟多个域名,第一个是主域名。
Syntax: server_name_in_redirect on | off;
Default:
server_name_in_redirect off;
Context: http, server, location
在 nginx 发出的绝对重定向中启用或禁用由 server_name 指令指定的主域名的使用。 当禁用主域名时,将使用“Host”请求标头字段中的名称。 如果此字段不存在,则使用服务器的 IP 地址。
*泛域名:仅支持在最前或者最后,例如server_name *.amass.fun;
正则表达式:加~前缀,例如server_name www.amass.fun ~^www\d+\.amass\.fun$;
用正则表达式创建变量:用小括号(),例如
server {
server_name ~^(www\.)?(.+)$;
location / {
root /site/$2;
}
}
server {
server_name ~^(www\.)?(?<domain>.+)$;
location / {
root /site/$domain;
}
}
.amass.fun可以匹配amass.fun和*.amass.fun,_匹配所有,""匹配没有传递Host头部。
Server匹配顺序
- 精确匹配
*在前的泛域名*在后的泛域名- 按文件中的顺序匹配正则表达式域名
- default server
- 第一个
- listen指定default
HTTP请求的11个阶段
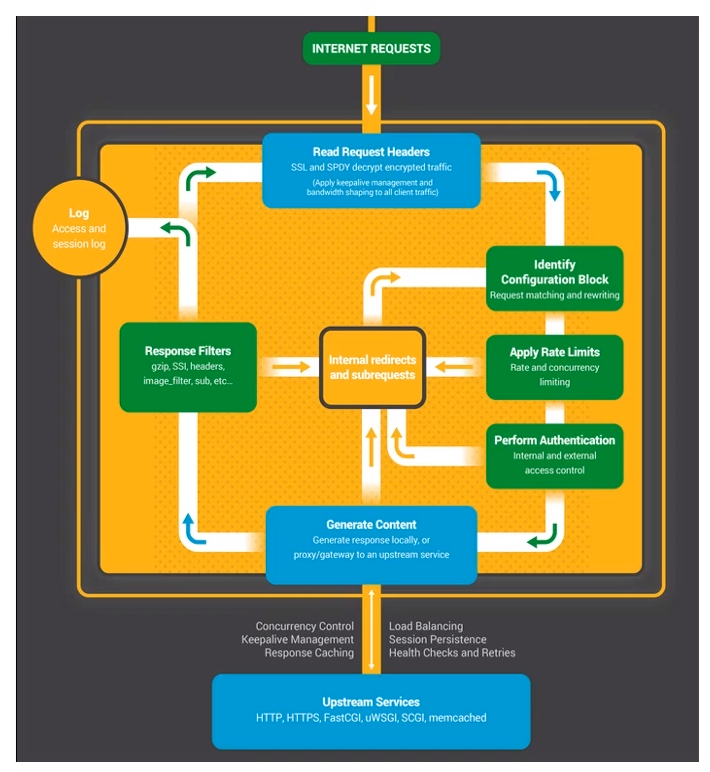
| 阶段 | 作用的模块 |
|---|---|
| POST_READ | realip |
| SERVER_REWRITE | rewrite |
| FIND_CONFIG | |
| REWRITE | rewrite |
| POST_REWRITE | |
| PREACCESS | limit_conn,limit_req |
| ACCESS | auth_basic,access,auth_request |
| POST_ACCESS | |
| PRECONTENT | try_files |
| CONTENT | index,autoindex,concat |
| LOG | access_log |
- POST_READ:在 read 完请求的头部之后,在没有对头部做任何处理之前,想要获取到一些原始的值,就应该在这个阶段进行处理。这里面会涉及到一个 realip 模块。
- SERVER_REWRITE:和下面的 REWRITE 阶段一样,都只有一个模块叫 rewrite 模块,一般没有第三方模块会处理这个阶段。
- FIND_CONFIG:做 location 的匹配,暂时没有模块会用到。
- REWRITE:对 URL 做一些处理。
- POST_WRITE:处于 REWRITE 之后,也是暂时没有模块会在这个阶段出现。
接下来是确认用户访问权限的三个模块:
- PREACCESS:是在 ACCESS 之前要做一些工作,例如并发连接和 QPS 需要进行限制,涉及到两个模块:limt_conn 和 limit_req
- ACCESS:核心要解决的是用户能不能访问的问题,例如 auth_basic 是用户名和密码,access 是用户访问 IP,auth_request 根据第三方服务返回是否可以去访问。
- POST_ACCESS:是在 ACCESS 之后会做一些事情,同样暂时没有模块会用到。 最后的三个阶段处理响应和日志:
- PRECONTENT:在处理 CONTENT 之前会做一些事情,例如会把子请求发送给第三方的服务去处理,try_files 模块也是在这个阶段中。
- CONTENT:这个阶段涉及到的模块就非常多了,例如 index, autoindex, concat 等都是在这个阶段生效的。
- LOG:记录日志 access_log 模块。
以上的这些阶段都是严格按照顺序进行处理的,当然,每个阶段中各个 HTTP 模块的处理顺序也很重要,如果某个模块不把请求向下传递,后面的模块是接收不到请求的。而且每个阶段中的模块也不一定所有都要执行一遍,下面就接着讲一下各个阶段模块之间的请求顺序。
11个阶段的顺序处理
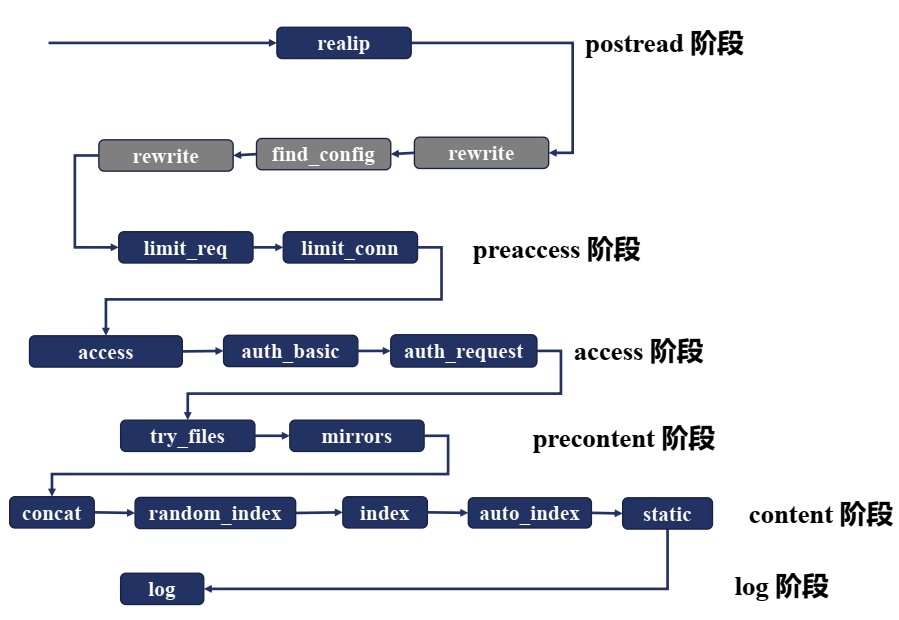
如下图所示,每一个模块处理之间是有序的,那么这个顺序怎么才能得到呢?其实非常简单,在源码 ngx_module.c 中,有一个数组 ngx_module_name,其中包含了在编译 Nginx 的时候的 with 指令所包含的所有模块,它们之间的顺序非常关键,在数组中顺序是相反的。
char *ngx_module_names[] = {
// ...
"ngx_http_static_module",
"ngx_http_autoindex_module",
"ngx_http_index_module",
"ngx_http_random_index_module",
"ngx_http_mirror_module",
"ngx_http_try_files_module",
"ngx_http_auth_request_module",
"ngx_http_auth_basic_module",
"ngx_http_access_module",
"ngx_http_limit_conn_module",
"ngx_http_limit_req_module",
"ngx_http_realip_module",
"ngx_http_referer_module",
"ngx_http_rewrite_module",
"ngx_http_concat_module",
//...
}
灰色部分的模块是 Nginx 的框架部分去执行处理的,第三方模块没有机会在这里得到处理。
在依次向下执行的过程中,也可能不按照这样的顺序。例如,在 access 阶段中,有一个指令叫 satisfy,它可以指示当有一个满足的时候就直接跳到下一个阶段进行处理,例如当 access 满足了,就直接跳到 try_files 模块进行处理,而不会再执行 auth_basic、auth_request 模块。
在 content 阶段中,当 index 模块执行了,就不会再执行 auto_index 模块,而是直接跳到 log 模块。
POSTREAD阶段:获取真实客户端地址的realip模块
postread 阶段,是 11 个阶段的第 1 个阶段,这个阶段刚刚获取到了请求的头部,还没有进行任何处理,我们可以拿到一些原始的信息。例如,拿到用户的真实 IP 地址。
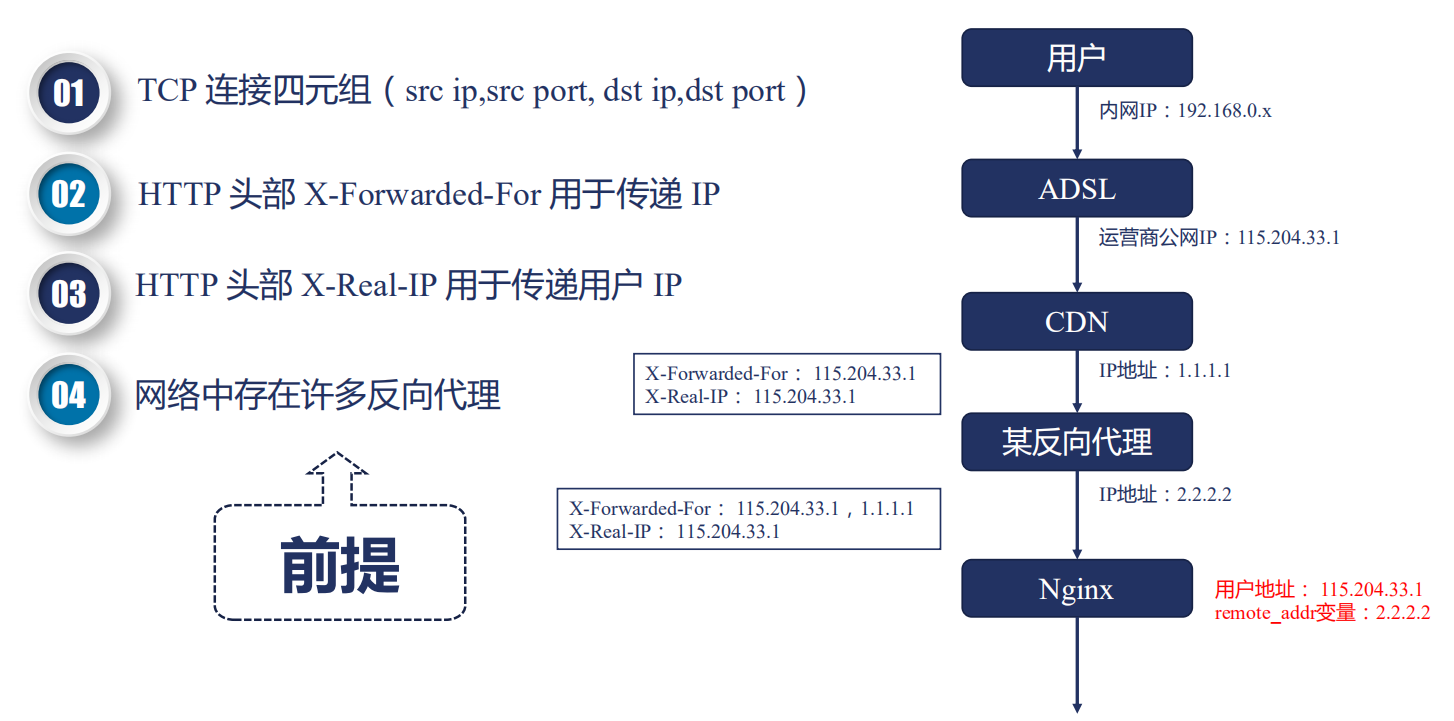
我们知道,TCP 连接是由一个四元组构成的,在四元组中,包含了源 IP 地址。而在真实的互联网中,存在非常多的正向代理和反向代理。例如最终的用户有自己的内网 IP 地址,运营商会分配一个公网 IP,然后访问某个网站的时候,这个网站可能使用了 CDN 加速一些静态文件或图片,如果 CDN 没有命中,那么就会回源,回源的时候可能还要经过一个反向代理,例如阿里云的 SLB,然后才会到达 Nginx。
我们要拿到的地址应该是运营商给用户分配的公网 IP 地址 115.204.33.1,对这个 IP 来进行并发连接的控制或者限速,而 Nginx 拿到的却是 2.2.2.2,那么怎么才能拿到真实的用户 IP 呢?
HTTP 协议中,有两个头部可以用来获取用户 IP:
- X-Forwardex-For 是用来传递 IP 的,这个头部会把经过的节点 IP 都记录下来
- X-Real-IP:可以记录用户真实的 IP 地址,只能有一个
拿到真实用户 IP 后如何使用?,针对这个问题,Nginx 是基于变量来使用。
例如 binary_remote_addr、remote_addr 这样的变量,其值就是真实的 IP,这样做连接限制也就是 limit_conn 模块才有意义,这也说明了,limit_conn 模块只能在 preaccess 阶段,而不能在 postread 阶段生效。
realip 模块
Syntax: set_real_ip_from address | CIDR | unix:;
Default: —
Context: http, server, location
Syntax: real_ip_header field | X-Real-IP | X-Forwarded-For | proxy_protocol;
Default: real_ip_header X-Real-IP;
Context: http, server, location
Syntax: real_ip_recursive on | off;
Default: real_ip_recursive off;
Context: http, server, location
- 默认不会编译进 Nginx,需要通过 --with-http_realip_module 启用功能
- 变量:如果还想要使用原来的 TCP 连接中的地址和端口,需要通过这两个变量保存realip_remote_addr、realip_remote_port
- 功能:修改客户端地址
- 指令
- set_real_ip_from 指定可信的地址,只有从该地址建立的连接,获取的 realip 才是可信的
- real_ip_header 指定从哪个头部取真实的 IP 地址,默认从 X-Real-IP 中取,如果设置从 X-Forwarded-For 中取,会先从最后一个 IP 开始取
- real_ip_recursive 环回地址,默认关闭,打开的时候,如果 X-Forwarded-For 最后一个地址与客户端地址相同,会过滤掉该地址
上面关于 real_ip_recursive 指令可能不太容易理解,我们来实战练习一下,先来看 real_ip_recursive 默认关闭的情况:
# 在 example 目录下建立 realip.conf,set_real_ip_from 可以设置为自己的本机 IP
server {
listen 80;
server_name amass.fun;
error_log /root/http_server/logs/error.log debug;
set_real_ip_from 192.168.0.108;
#real_ip_header X-Real-IP;
real_ip_recursive off;
# real_ip_recursive on;
real_ip_header X-Forwarded-For;
location / {
return 200 "Client real ip: $remote_addr\n";
}
}
重载完配置文件后,测试相应结果
curl -H 'X-Forwarded-For: 1.1.1.1,192.168.0.108' amass.fun
Client real ip: 192.168.0.108
如果real_ip_recursive on的话,测试
curl -H 'X-Forwarded-For: 1.1.1.1,2.2.2.2,192.168.0.108' ziyang.realip.com
Client real ip: 2.2.2.2
所以这里面也可看出来,如果使用 X-Forwarded-For 获取 realip 的话,需要打开 real_ip_recursive,并且,realip 依赖于 set_real_ip_from 设置的可信地址。
那么有人可能就会问了,那直接用 X-Real-IP 来选取真实的 IP 地址不就好了。这是可以的,但是 X-Real-IP 是 Nginx 独有的,不是 RFC 规范,如果客户端与服务器之间还有其他非 Nginx 软件实现的代理,就会造成取不到 X-Real-IP 头部,所以这个要根据实际情况来定。
REWRITE阶段的rewrite模块:return指令
return 指令的语法如下:
Syntax: return code [text];
return code URL;
return URL;
Default: —
Context: server, location, if
- 返回状态码,后面跟上 body
- 返回状态码,后面跟上 URL
- 直接返回 URL
返回状态码包括以下几种:
- Nginx 自定义
- 444:立刻关闭连接,用户收不到响应
- HTTP 1.0 标准
- 301:永久重定向
- 302:临时重定向,禁止被缓存
- HTTP 1.1 标准
- 303:临时重定向,允许改变方法,禁止被缓存
- 307:临时重定向,不允许改变方法,禁止被缓存
- 308:永久重定向,不允许改变方法
error_page 的作用大家肯定经常见到。当访问一个网站出现 404 的时候,一般不会直接出现一个 404 NOT FOUND,而是会有一个比较友好的页面,这就是 error_page 的功能。
Syntax: error_page code ... [=[response]] uri;
Default: —
Context: http, server, location, if in location
我们来看几个例子:
1. error_page 404 /404.html;
2. error_page 500 502 503 504 /50x.html;
3. error_page 404 =200 /empty.gif;
4. error_page 404 = /404.php;
5. location / {
error_page 404 = @fallback;
}
location @fallback {
proxy_pass http://backend;
}
6. error_page 403 http://example.com/forbidden.html;
7. error_page 404 =301 http://example.com/notfound.html;
那么现在就会有两个问题,大家看下下面这个配置文件:
server {
server_name ziyang.return.com;
listen 80;
root html/;
error_page 404 /403.html;
#return 405;
location / {
#return 404 "find nothing!";
}
}
- 当 server 下包含 error_page 且 location 下有 return 指令的时候,会执行哪一个呢?
- return 指令同时出现在 server 块下和同时出现在 location 块下,它们有合并关系吗?
这两个问题我们通过实战验证一下。
- 将上面的配置添加到配置文件 return.conf
- 在本机的 hosts 文件中绑定 amass.return.com 为本地的 IP 地址
- 访问一个不存在的页面
curl ziyang.return.com/text
<html>
<head><title>403 Forbidden</title></head>
<body>
<center><h1>403 Forbidden</h1></center>
<hr><center>nginx/1.17.8</center>
</body>
</html>
这个时候可以看到,是 error_page 生效了,返回的响应是 403。
那么假如打开了 location 下 return 指令的注释呢?
打开 return 指令注释,reload 配置文件,重新访问页面
curl amass.return.com/text
find nothing!
这时候,return 指令得到了执行。也就是第一个问题,当 server 下包含 error_page 且 location 下有 return 指令的时候,会执行 return 指令。
下面再看一下 server 下的 return 指令和 location 下的 return 指令会执行哪一个。
- 打开 server 下 return 指令的注释,reload 配置文件
- 重新访问页面
curl ziyang.return.com/text
<html>
<head><title>405 Not Allowed</title></head>
<body>
<center><h1>405 Not Allowed</h1></center>
<hr><center>nginx/1.17.8</center>
</body>
</html>
针对上面两个问题也就有了答案:
-
当 server 下包含 error_page 且 location 下有 return 指令的时候,会执行哪一个呢?
会执行 location 下的 return 指令。
-
return 指令同时出现在 server 块下和同时出现在 location 块下,它们有合并关系吗?
没有合并关系,先遇到哪个 return 指令就先执行哪一个。
REWRITE阶段的rewrite模块:重写URL
rewrite 指令用于修改用户传入 Nginx 的 URL。来看下 rewrite 的指令规则:
Syntax: rewrite regex replacement [flag];
Default: —
Context: server, location, if
它的功能主要有下面几点:
- 将 regex 指定的 URL 替换成 replacement 这个新的 URL
- 可以使用正则表达式及变量提取
- 当 replacement 以 http:// 或者 https:// 或者 $schema 开头,则直接返回 302 重定向
- 替换后的 URL 根据 flag 指定的方式进行处理
- last:用 replacement 这个 URL 进行新的 location 匹配
- break:break 指令停止当前脚本指令的执行,等价于独立的 break 指令
- redirect:返回 302 重定向
- permanent:返回 301 重定向
指令示例,现在我们有这样的一个目录结构:
html/first/
└── 1.txt
html/second/
└── 2.txt
html/third/
└── 3.txt
配置文件如下所示:
server {
listen 80;
server_name rewrite.amass.com;
rewrite_log on;
error_log logs/rewrite_error.log notice;
root html/;
location /first {
rewrite /first(.*) /second$1 last;
return 200 'first!\n';
}
location /second {
rewrite /second(.*) /third$1;
return 200 'second!\n';
}
location /third {
return 200 'third!\n';
}
location /redirect1 {
rewrite /redirect1(.*) $1 permanent;
}
location /redirect2 {
rewrite /redirect2(.*) $1 redirect;
}
location /redirect3 {
rewrite /redirect3(.*) http://rewrite.ziyang.com$1;
}
location /redirect4 {
rewrite /redirect4(.*) http://rewrite.ziyang.com$1 permanent;
}
}
那么我们的问题是:
- return 指令 与 rewrite 指令的顺序关系?
- 访问 /first/3.txt,/second/3.txt,/third/3.txt 分别返回的是什么?
- 如果不携带 flag 会怎么样?
带着这三个问题,我们来实际演示一下。将上面的配置添加到配置文件 rewrite.conf,在本机的 hosts 文件中绑定 rewrite.amass.com 为 127.0.0.1
last flag:首先访问 rewrite.amss.com/first/3.txt,结果如下:
curl rewrite.ziyang.com/first/3.txt
second!
为什么结果是 second! 呢?应该是 third! 呀,可能有人会有这样的疑问。实际的匹配步骤如下:
- curl rewrite.amass.com/first/3.txt
- 由于 rewrite /first(.*) /second$1 last; 这条指令的存在,last 表示使用新的 URL 进行 location 匹配,因此接下来会去匹配 second/3.txt
- 匹配到 /second 块之后,会依次执行指令,最后返回 200
- 注意,location 块中虽然也改写了 URL,但是并不会去继续匹配,因为后面没有指定 flag。
break flag:下面将 rewrite /second(.*) /third$1; 这条指令加上 break flag,rewrite /second(.*) /third$1 break;
继续访问 rewrite.ziyang.com/first/3.txt,结果如下:
curl rewrite.ziyang.com/first/3.txt
test3
这时候返回的是 3.txt 文件的内容 test3。实际的匹配步骤如下:
- curl rewrite.amass.com/first/3.txt
- 由于 rewrite /first(.*) /second$1 last; 这条指令的存在,last 表示使用新的 URL 进行 location 匹配,因此接下来会去匹配 second/3.txt
- 匹配到 /second 块之后,由于 break flag 的存在,会继续匹配 rewrite 过后的 URL
- 匹配 /third location
因此,这个过程实际请求的 URL 是 rewrite.ziyang.com/third/3.txt,这样自然结果就是 test3 了。你还可以试试访问 rewrite.ziyang.com/third/2.txt 看看会返回什么。
redirect 和 permanent flag
配置文件中还有 4 个 location,你可以分别试着访问一下,结果是这样的:
- redirect1:返回 301
- redirect2:返回 302
- redirect3:返回 302
- redirect4:返回 301
rewrite 行为记录日志,主要是一个指令 rewrite_log:
Syntax: rewrite_log on | off;
Default: rewrite_log off;
Context: http, server, location, if
这个指令打开之后,会把 rewrite 的日志写入 logs/rewrite_error.log 日志文件中,这是请求 /first/3.txt 的日志记录:
2020/05/06 06:24:05 [notice] 86959#0: *25 "/first(.*)" matches "/first/3.txt", client: 127.0.0.1, server: rewrite.amass.com, request: "GET /first/3.txt HTTP/1.1", host: "rewrite.amass.com"
2020/05/06 06:24:05 [notice] 86959#0: *25 rewritten data: "/second/3.txt", args: "", client: 127.0.0.1, server: rewrite.amass.com, request: "GET /first/3.txt HTTP/1.1", host: "rewrite.amass.com"
2020/05/06 06:24:05 [notice] 86959#0: *25 "/second(.*)" matches "/second/3.txt", client: 127.0.0.1, server: rewrite.amass.com, request: "GET /first/3.txt HTTP/1.1", host: "rewrite.amass.com"
2020/05/06 06:24:05 [notice] 86959#0: *25 rewritten data: "/third/3.txt", args: "", client: 127.0.0.1, server: rewrite.amass.com, request: "GET /first/3.txt HTTP/1.1", host: "rewrite.amass.com"
REWRITE阶段的rewrite模块:条件判断
if 指令也是在 rewrite 阶段生效的,它的语法如下所示:
Syntax: if (condition) { ... }
Default: —
Context: server, location
它的规则是:
- 条件 condition 为真,则执行大括号内的指令;同时还遵循值指令的继承规则(详见我之前的文章 Nginx 的配置指令)
那么 if 指令的条件表达式包含哪些内容呢?它的规则如下:
- 检查变量为空或者值是否为 0
- 将变量与字符串做匹配,使用 = 或 !=
- 将变量与正则表达式做匹配
- 大小写敏感,~ 或者 !~
- 大小写不敏感,* 或者 !*
- 检查文件是否存在,使用 -f 或者 !-f
- 检查目录是否存在,使用 -d 或者 !-d
- 检查文件、目录、软链接是否存在,使用 -e 或者 !-e
- 检查是否为可执行文件,使用 -x 或者 !-x
下面是一些例子:
if ($http_user_agent ~ MSIE) { # 与变量 http_user_agent 匹配
rewrite ^(.*)$ /msie/$1 break;
}
if ($http_cookie ~* "id=([^;]+)(?:;|$)") { # 与变量 http_cookie 匹配
set $id $1;
}
if ($request_method = POST) { # 与变量 request_method 匹配,获取请求方法
return 405;
}
if ($slow) { # slow 变量在 map 模块中自定义,也可以进行匹配
limit_rate 10k;
}
if ($invalid_referer) {
return 403;
}
find_config阶段
当经过 rewrite 模块,匹配到 URL 之后,就会进入 find_config 阶段,开始寻找 URL 对应的 location 配置。
location指令语法
Syntax: location [ = | ~ | ~* | ^~ ] uri { ... }
location @name { ... }
Default: —
Context: server, location
Syntax: merge_slashes on | off;
Default: merge_slashes on;
Context: http, server
这里面有一个 merge_slashes 指令,这个指令的作用是,加入 URL 中有两个重复的 /,那么会合并为一个,这个指令默认是打开的,只有当对 URL 进行 base64 之类的编码时才需要关闭。
location匹配规则
location 的匹配规则是仅匹配 URI,忽略参数,有下面三种大的情况:
- 前缀字符串
- 常规匹配
- =:精确匹配
- ^~:匹配上后则不再进行正则表达式匹配
- 正则表达式
- ~:大小写敏感的正则匹配
- ~*:大小写不敏感
- 用户内部跳转的命名 location
- @
先看一下 Nginx 的配置文件:
server {
listen 80;
server_name location.ziyang.com;
error_log logs/error.log debug;
#root html/;
default_type text/plain;
merge_slashes off;
location ~ /Test1/$ {
return 200 'first regular expressions match!\n';
}
location ~* /Test1/(\w+)$ {
return 200 'longest regular expressions match!\n';
}
location ^~ /Test1/ {
return 200 'stop regular expressions match!\n';
}
location /Test1/Test2 {
return 200 'longest prefix string match!\n';
}
location /Test1 {
return 200 'prefix string match!\n';
}
location = /Test1 {
return 200 'exact match!\n';
}
}
访问下面几个 URL 会分别返回什么内容呢?
/Test1
/Test1/
/Test1/Test2
/Test1/Test2/
/test1/Test2
例如访问 /Test1 时,会有几个部分都匹配上:
- 常规前缀匹配:location /Test1
- 精确匹配:location = /Test1
访问 /Test1/ 时,也会有几个部分匹配上:
- location ~ /Test1/$
- location ^~ /Test1/
那么究竟会匹配哪一个呢?Nginx 其实是遵循一套规则的,如下图所示:
全部的前缀字符串是放置在一棵二叉树中的,Nginx 会分为两部分进行匹配:
- 先遍历所有的前缀字符串,选取最长的一个前缀字符串,如果这个字符串是 = 的精确匹配或 ^~ 的前缀匹配,会直接使用
- 如果第一步中没有匹配上 = 或 ^~,那么会先记住最长匹配的前缀字符串 location
- 按照 nginx.conf 文件中的配置依次匹配正则表达式
- 如果所有的正则表达式都没有匹配上,那么会使用最长匹配的前缀字符串
下面看下实际的响应是怎么样的:
curl location.ziyang.com/Test1
# exact match!
curl location.ziyang.com/Test1/
# stop regular expressions match!
curl location.ziyang.com/Test1/Test2
# longest regular expressions match!
curl location.ziyang.com/Test1/Test2/
# longest prefix string match!
curl location.ziyang.com/Test1/Test3
# stop regular expressions match!
- /Test1 匹配 location = /Test1
- /Test1/ 匹配 location ^~ /Test1/
- /Test1/Test2 匹配 location ~* /Test1/(\w+)$
- /Test1/Test2/ 匹配 location /Test1/Test2
- /Test1/Test3 匹配 location ^~ /Test1/
这里面重点解释一下 /Test1/Test3 的匹配过程:
- 遍历所有可以匹配上的前缀字符串,总共有两个
- ^~ /Test1/
- /Test1
- 选取最长的前缀字符串 /Test1/,由于前面有 ^~ 禁止正则表达式匹配,因此直接使用 location ^~ /Test1/ 的规则
- 返回 stop regular expressions match!
OpenResty
OpenResty 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
Nginx [engine x] 是一个 HTTP 和反向代理服务器、邮件代理服务器和通用 TCP/UDP 代理服务器。
安装
sudo apt-get -y install --no-install-recommends wget gnupg ca-certificates
wget -O - https://openresty.org/package/pubkey.gpg | sudo gpg --dearmor -o /usr/share/keyrings/openresty.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/openresty.gpg] http://openresty.org/package/ubuntu $(lsb_release -sc) main" | sudo tee /etc/apt/sources.list.d/openresty.list > /dev/null
sudo apt-get update
sudo apt-get -y install openresty
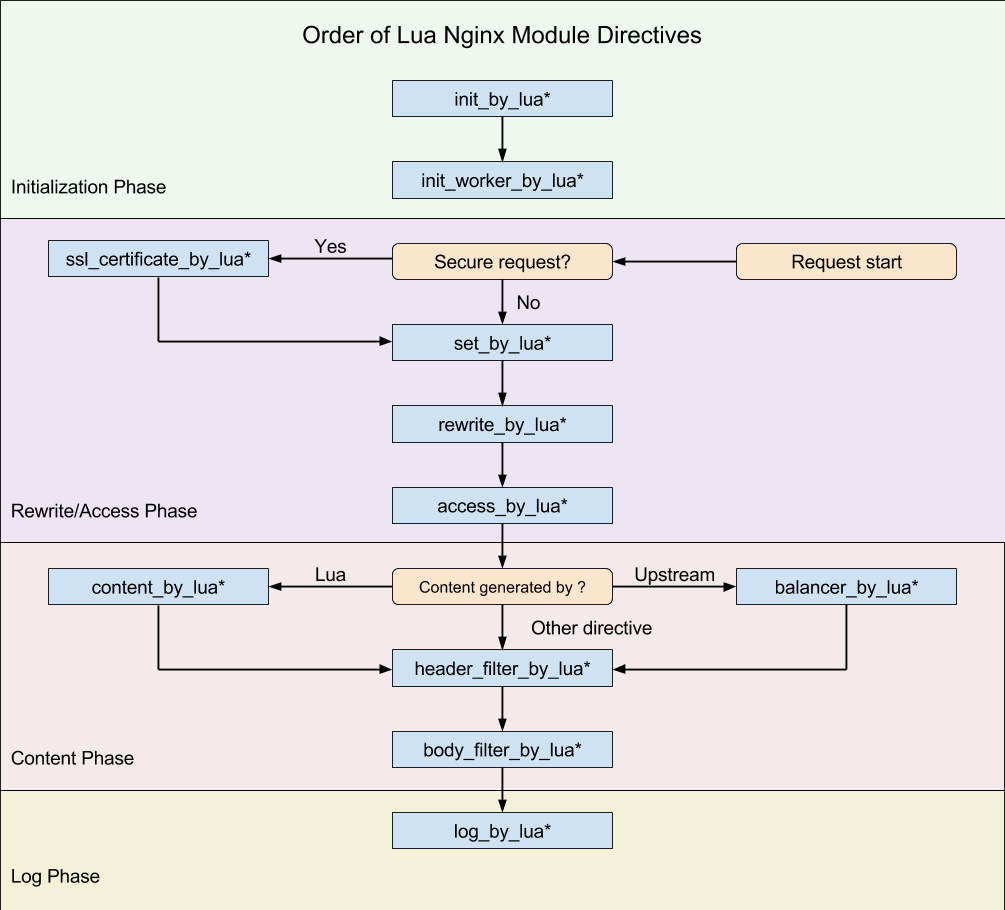
下图是 lua-nginx-module 的一张图片。其中,init_by_lua 只会在 Master 进程被创建时执行,init_worker_by_lua 只会在每个 Worker 进程被创建时执行。其他的 *_by_lua 指令则是由终端请求触发,会被反复执行。
所以在 init_by_lua 阶段,我们可以预先加载 Lua 模块和公共的只读数据,这样可以利用操作系统的 COW(copy on write)特性,来节省一些内存。
对于业务代码来说,其实大部分的操作都可以在 content_by_lua 里面完成,但我更推荐的做法,是根据不同的功能来进行拆分,比如下面这样:
- set_by_lua:设置变量;
- rewrite_by_lua:转发、重定向等;
- access_by_lua:准入、权限等;
- content_by_lua:生成返回内容;
- header_filter_by_lua:应答头过滤处理;
- body_filter_by_lua:应答体过滤处理;
- log_by_lua:日志记录。
NanoMQ
NanoMQ是2021年1月发布的开源边缘计算项目,是面向物联网边缘计算场景的下一代轻量级、高性能MQTT消息代理。
Github仓库地址:https://github.com/emqx/nanomq
NanoMQ 与 NNG 合作。 依托NNG优秀的网络API设计,NanoMQ可以专注于MQTT代理性能和更多扩展功能。 目标是在边缘设备和MEC中提供更好的SMP支持和高性价比。 未来计划添加其他物联网协议,例如 ZMQ、NanoMSG 和 SP。
使用 MQTTX 测试 MQTT 服务。
NNG
NNG 是一个轻量级、无需中间件(Broker-less)的库,它提供了一个简单的 API 来解决常见重复的消息传递问题,例如发布/订阅、RPC 请求/回复或服务发现。该 API 使我们无需担心连接管理、重试和其他常见注意事项等细节,因此可以使我们专注于应用程序而不是通讯过程。
- 可靠性:NNG 从一开始就专为生产使用而设计。考虑到每种错误情况,并且设计为避免崩溃,除非出现严重的开发人员错误。
- 可扩展性:NNG 使用定制的异步 I/O 框架进行扩展以使用多个核心,并使用线程池来分散负载。
- 可维护性:NNG 的架构采用模块化设计,即使不熟悉代码库的开发人员也可以轻松掌握。代码也有很好的文档记录。
- 可扩展性:由于它避免了与文件描述符的绑定,并避免了令人困惑的互锁状态机,因此更容易向 NNG 添加新的协议和传输。该特性通过添加 TLS 和 ZeroTier 传输得到了证明。
- 安全性:NNG 提供 TLS 1.2 和 ZeroTier 传输,支持强大且符合行业标准的身份验证和加密。此外,它还经过强化,能够抵御恶意攻击者,并在某些恶劣的互联网环境中使用做了特殊优化。
NNG提供了六种传输协议:
- Pair - 点对点通信。
- PubSub - 发布/订阅模式。
- ReqRep - 请求/回复模式。
- Push/Pull - 用于负载分配的模式,其中 Push 端发送消息,Pull 端接收消息。
- Survey - 调查模式,允许请求者询问多个应答者。
- Bus - 总线模式,允许多对多通信。
NNG提供了七种传输方式:
- Inproc - 进程内通信。
- IPC - 进程间通信。
- TCP - 基于 TCP 的网络通信。
- TLS over TCP - 基于 tsl 加密 的 tcp socket 通信。
- WebSocket - 基于 WebSocket 的通信。
- BSD Socket - 支持BSD Socket API。
- ZeroTier - 支持 zerotier 网络。
在使用TLS时,应尽可能使用 nng_tls_config_* 而不是通过 nng_listener_set_* 使用 NNG_OPT_TLS_CA_FILE、NNG_OPT_TLS_CERT_KEY_FILE:
nng_tls_config *config = nullptr;
nng_tls_config_alloc(&config, NNG_TLS_MODE_SERVER);
nng_tls_config_ca_file(config, "resources/ca-cert.pem");
nng_tls_config_cert_key_file(config, "resources/server-cert-key.pem", NULL);
nng_listener_set_ptr(listener, NNG_OPT_TLS_CONFIG, config);
nng_tls_config_free(config);
在使用 dialer 时,使用 :
nng_dialer_set_string(dialer, NNG_OPT_TLS_CA_FILE, "resources/ca-cert.pem");
无法与服务器正常进行TLS握手,但是使用:
nng_tls_config *config = nullptr;
nng_tls_config_alloc(&config, NNG_TLS_MODE_CLIENT);
nng_tls_config_ca_file(config, "resources/ca-cert.pem");
nng_dialer_set_ptr(dialer, NNG_OPT_TLS_CONFIG, config);
nng_tls_config_free(config);
是表现正常的。
C++ Web Toolkit
Wt, C++ Web Toolkit 提供了使用 C++ 构建 Web 应用程序的方法,它提供了 Qt 风格的 API,便于理解。
Wt 支持三种部署方式:httpd、FastCGI、ISAPI。这里更推荐使用 Wt 的内置实现 httpd 服务器,这样便于调试,同时也支持 WebSocket,理论上使用 WebSocket 能够使 Wt 的 WebUI 交互更流畅,相比于使用 AJAX 一直像 Wt 请求实时状态更新。
在使用 wt 时,需要注意的就是:--docroot、--resources-dir、--approot、--deploy-path
-
--approot:该路径用于存放 Web 浏览器不需获取,但应用程序内部需要使用的文件。例如 消息资源包 (Message Resource Bundles,xml)、CSV 文件、数据库文件(例如Wt::Dbo的 SQLite 文件)...如果该参数没有指定,则默认为 Wt 应用程序的工作路径,即应用程序运行的当前目录。
messageResourceBundle().use(appRoot() + "text");
messageResourceBundle().use(appRoot() + "charts");
auto sqlite3_ = std::make_unique<Wt::Dbo::backend::Sqlite3>(appRoot() + "planner.db"); -
--deploy-path:指定 Wt 应用程序部署在哪个路径,默认是/。 -
--docroot:指定 Web 静态文件.html、.css等存放路径根目录。可以在指定的根目录后加上;,然后加上以,分隔的静态文件路径列表(即使它们位于部署路径内)。例如:--docroot=.;/favicon.ico,/resources,/style -
--resources-dir:Wt内部使用的resources文件夹的路径。默认情况下,Wt 将在--docroot的resources子文件夹中查找其资源。如果在该资源文件夹中未找到文件,则将检查此文件夹作为后备(fallback机制)。如果省略此选项,则 Wt 将不使用后备(fallback)资源文件夹。
当 Wt 应用程序部署在以/结尾的路径(即文件夹路径)时,只有与请求的 URL 完全匹配才会路由到应用程序本身。此行为避免了在/部署应用程序,导致 Web 服务器将无法提供任何静态文件。同时,将为内部路径(Internal Path)生成以?_=起始的丑陋的 URL。
// 第二个参数不填则默认为 /
addEntryPoint(EntryPointType::Application,createApplication);
即我们以上面的方式部署我们的应用时,只有访问 http://localhost:8080/ 才能访问,如果这个时候我们调用 WApplication::setInternalPath()时,内部会生成形如 http://localhost:8080/?_=/custom/path 的URL路径。且访问http://localhost:8080/app、http://localhost:8080/app/login、http://localhost:8080/custom/path 等地址时,是匹配不到我们部署的应用程序的,这个时候 Wt 会在 --docroot 查找是否有静态资源文件,如果没有则返回 404。
而我们部署在:
addEntryPoint(EntryPointType::Application,createApplication, "wt");
则 http://localhost:8080/wt、http://localhost:8080/wt/app、http://localhost:8080/wt/**任何在 /wt 下的路径都能访问到我们部署的应用程序。内部路径跳转也是生成 http://localhost:8080/wt/custom/path 这样的标准 url。
所以,问题是为什么部署在 / 下,则表现和我们所期望的不一致呢?(即我们所设想的是部署在 / 下时,任何路径都应指向到我们部署的应用程序。)
问题的原因就在于开头所述,即:
Wt 不止提供应用程序部署,同时也支持提供静态资源文件的托管。
如果 Wt 实现的如我们所设想的这样,那么当我们部署在 / 下时,访问任何路径都将指向我们的应用,它就彻底失去了托管静态 html 文件的能力。这也是部署在 / 的应用程序内部路径 Wt 会自动加上 ugly url ?_= 前缀的原因。
从 Wt 3.1.9 版本开始,支持通过在 --docroot 中显示列出其目录包含静态源的子文件夹(用法如前对 --docroot 介绍时所述),就可以在/部署时,不再使用 ?_= 的 ugly url 方式解决上述问题。 例如当应用程序部署在 / 时,当我们访问 /app/login ,Wt 会先检查 /docroot/app 是否为静态资源文件夹,如果不是,则指向到我们部署的应用程序。
编译示例程序
在使用 Wt 构建 Web UI 时,其提供的很多控件我们并不是太清楚其样式,以及如何使用。所以,能够运行其示例代码是很重要的一步。
进入其源码目录,使用 CMake 编译构建:
cmake -G Ninja -B build -S . -DCMAKE_BUILD_TYPE=Debug -DCMAKE_INSTALL_PREFIX=$(pwd)/app \
-DENABLE_QT4=OFF -DENABLE_QT5=OFF -DENABLE_QT6=OFF -DINSTALL_EXAMPLES=ON \
-DBOOST_ROOT=/opt/Libraries/boost_1_86_0
cmake --build build --target all
cmake --install build
构建完成后,示例位于 /app/lib/Wt/examples 下。以 widgetgallery 为例,直接运行 /app/lib/Wt/examples/widgetgallery/widgetgallery 即可。
Wt::Dbo
Wt::Dbo 是一个 C++ ORM(对象关系映射)库。该库作为 Wt 的一部分,用于构建数据库驱动的 Web 应用程序,但也可以独立使用。
该库提供了基于类的数据库表视图,通过插入、更新和删除数据库记录,使数据库对象的对象层次结构与数据库自动同步。C++ 类映射到数据库表,类字段映射到数据表列,指针和指针集合映射到数据库关系。映射类的对象称为数据库对象 (dbo)。查询结果可以根据数据库对象、基本数据类型或这些基本数据类型的元组来定义。
Wt::Dbo 使用现代 C++ 方法来解决映射问题。映射完全用 C++ 代码定义,而不是依靠基于 XML 的描述或者使用晦涩难懂的宏来描述 C++ 类和字段应如何映射到表和列。
Wt::Dbo::Session 对象是一个长期存在的对象,可用于访问我们的数据库对象。通常会为应用程序会话的整个生命周期创建一个 Session 对象,��每个用户创建一个。Wt::Dbo 命名空间下的类都不是线程安全的(连接池除外),并且 Wt::Dbo::Session 对象不会在会话之间共享。
Wt::Dbo::Session 对象会获得一个连接,可用于与数据库通信。Wt::Dbo::Session 对象仅在事务期间使用连接,因此实际上不需要专用连接。当计划进行多个并发会话时,使用连接池是有意义的,并且Wt::Dbo::Session 对象也可以使用对连接池的引用进行构造。
C++类的映射
#include <Wt/Wt::Dbo/Wt::Dbo.h>
#include <string>
enum class Role {
Visitor = 0,
Admin = 1,
Alien = 42
};
class User {
public:
std::string name;
std::string password;
Role role;
int karma;
template<class Action>
void persist(Action& a) {
Wt::Dbo::field(a, name, "name");
Wt::Dbo::field(a, password, "password");
Wt::Dbo::field(a, role, "role");
Wt::Dbo::field(a, karma, "karma");
}
};
模板成员函数 persist() 提供了 User 类的持久化定义,Wt::Dbo::field() 函数提供了类成员变量到数据表列的映射。
Wt::Dbo 支持标准 C++ 类型的映射,例如 int、std::string 和 enum 类型(可以在 Wt::Dbo::sql_value_traits<T> 的文档中找到支持类型的完整列表)。可以通过特化 Wt::Dbo::sql_value_traits<T> 来添加对其他类型的支持。目前还支持内置 Wt 类型,例如 WDate、WDateTime、WTime 和 WString,可以通过包含 <Wt/Dbo/WtSqlTraits.h> 来启用映射支持。
Wt::Dbo 定义了许多操作(Action),这些操作将使用其 persist() 方法应用于数据库对象,该方法依次应用于其所有成员。然后,这些操作将读取、更新或插入数据库对象、创建数据表或传播事务结果。
CSS
推荐一个前端CSS框架:Bulma。Bulma 是一个移动端优先得 CSS 框架,其实现主要使用了 CSS 的 Flexbox 布局。所以,这也给我们一个提示,要想在现在 PC Mobile 的 Web 时代,要想让页面自适应,就得数量掌握 CSS 的 Flexbox 布局。
Cookie 和 Session
Cookie和Session是什么呢? HTTP是一种无状态协议,而Cookie和Session可以弥补 HTTP 的无状态特性。
Cookie是客户端请求服务端时,由服务端创建并由客户端存储和管理的小文本文件。具体流程如下:
- 客户端首次发起请求。
- 服务端通过HTTP响应头里Set-Cookie字段返回Cookie信息。
- 客户端再发起请求时会通过HTTP请求头里Cookie字段携带Cookie信息
Session是客户端请求服务端时服务端会为这次请求创建一个数据结构,这个结构可以通过内存、文件、数据库等方式保存。具体流程如下:
- 客户端首次发起请求。
- 服务端收到请求并自动为该客户端创建特定的Session并返回SessionID,用来标识该客户端。
- 客户端通过服务端响应获取SessionID,并在后续请求携带SessionID。
- 服务端根据收到的SessionID,在服务端找对应的Session,进而获取到客户端信息。
基于Cookie和Session的登录态方案
什么是登录态?
主流Web应用比如浏览器是基于http协议的,而http协议是 无状态 的。什么是 无状态?就是服务器不知道是谁发送了这个http请求,无法识别区分用户身份。
所以登录态就是服务端用来区分用户身份,同时对用户进行记录的技术方案。
那怎么实现用户的登录态呢?常见的实现流程如下:
- 客户端用户输入登录凭据(如账户和密码),发送登录请求。
- 服务端校验用户是否合法(如认证和鉴权),合法后返回登录态,不合法返回第1步。
- 合法后携带登录态访问用户数据。
常见使用Cookie和Session认证流程如下:
- 客户端向服务端发送认证信息(例如账号密码)
- 服务端根据客户端提供的认证信息执行验证逻辑,如果验证成功则生成Session并保存,同时通过响应头Set-Cookie字段返回对应的SessionID
- 客户端再次请求并在Cookie里携带SessionID。
- 服务端根据SessionID查找对应的Session,并根据业务逻辑返回相应的数据。
Cookie和Session认证优点:
- Cookie由客户端管理,支持设定有效期、安全加密、防篡改、请求路径等属性。
- Session由服务端管理,支持有效期,可以存储各类数据。
Cookie和Session认证缺点
- Cookie只能存储字符串,有大小和数量限制,对移动APP端支持不好,同时有跨域限制(主域不同)。
- Session存储在服务端,对服务端有性能开销,客户端量太大会影响性能。如果集中存储(如存储在Redis),会带来额外的部署维护成本。